Abbildung 2.1: Komponenten einer logischen Sprache
Der vorliegende Text behandelt die Prädikatenlogik der ersten Stufe mit Identität und darf als Zusammenfassung meines Logik-Tutoriums betrachtet werden. Ich bezweifle, dass der Text alleine das Erlernen seines Inhalts ermöglicht, und sei es nur deshalb, weil die vielen merkwürdigen Zeichen und Symbole ohne mündliche Erläuterung noch abschreckender wirken müssen, als sie mit einer solchen erscheinen mögen. Wie dem auch sei, als Möglichkeit, Fehler und Fehlstellen in der eigenen Mitschrift zu finden und ihre Folgen zu entschärfen, mag er herhalten. Zudem erlaubt er es, die wichtigsten Teile derjenigen Dinge, die während des Semesters aus Zeit- und Termingründen keine Erwähnung finden, anzubringen.
Mit Ausnahme der Formulierung stammt fast nichts in diesem Skriptum von mir. Der überwiegende Teil des hier geäußerten Wissens stammt aus Dr. Klaus Dethloffs Vorlesung „Einführung in die Logik“, der Rest großteils aus den im Literaturverzeichnis genannten Werken.
Fehlerberichte und Rückfragen bitte ich an die folgende Adresse zu richten:
Christian Gottschall
Elektropost: christian.gottschall@posteo.de
Internet: https://www.erpelstolz.at/christian/
Eine Aussage Aussage ist ein Satz einer natürlichen Sprache, der wahr oder falsch sein kann. In der Linguistik wird statt des Wortes „Aussage“ häufig „deklarativer Satz“ gebraucht. Aussagen sind „Es regnet“, „5+5=22“ oder „Es gibt keine größte Primzahl“. Keine Aussagen sind Sätze wie „Wie spät ist es?“, „Mahlzeit!“ oder „Blubb“.
Oft werden die Wörter „Aussage“ und „Satz“Satz in logischen Texten synonym gebraucht, so auch im vorliegenden. Das Wort „Satz“ bezeichnet daher von nun an nicht mehr irgendwelche Sätze, sondern nur noch Aussagen.
Ein AxiomAxiom ist eine Aussage, an die man so fest glaubt, dass man es nicht für nötig hält, sie zu beweisen.
Eine Aussage, die aus logischen Gründen stets wahr ist, wird TautologieTautologie genannt.
Ein Argument Argument ist eine Aneinanderreihung von Sätzen (Aussagen!). Einer dieser Sätze (in der Regel der letzte) ist die Konklusion, alle übrigen sind die Prämissen. Ein Argument ist gültig, wenn die Konklusion aus den Prämissen folgt, und ungültig, wenn dies nicht der Fall ist. Es gibt auch Argumente, in denen es eine Konklusion, aber keine Prämissen gibt.
Beispiel für ein gültiges Argument mit zwei Prämissen:
| Alle Menschen sind sterblich. | erste Prämisse | |
| Sokrates ist ein Mensch. | zweite Prämisse | |
| Also ist Sokrates sterblich. | Konklusion |
Beispiel für ein gültiges Argument ohne Prämissen:
| Entweder es regnet, oder es regnet nicht. |
Beispiel für ein ungültiges Argument ohne Prämissen:
| Logik ist uninteressant. |
Logik
In diesem Skriptum wird eine logische Sprache vorgestellt, die Sprache der Prädikatenlogik der ersten Stufe mit Identität. Eine Definition ist an dieser Stelle leider noch nicht möglich.
Als AussagenlogikAussagenlogik wird jener Teil der Prädikatenlogik bezeichnet, der die Beziehungen untersucht, die zwischen Aussagesätzen bestehen. Da die Aussagenlogik ein echtes Teilgebiet der Prädikatenlogik ist, wird in diesem Skriptum grundsätzlich jene behandelt und werden an geeigneter Stelle die Einschränkungen dieser genannt. Für den Anfang muss ich mich auf die Feststellung beschränken, dass die PrädikatenlogikPrädikatenlogik im Gegensatz zur Aussagenlogik auch die innere Struktur der Aussagen näher betrachtet.1
Wenn man sich wissenschaftlich mit einer Sprache beschäftigt, dann ist es wichtig, zwischen Objektsprache und Metasprache zu unterscheiden. Die ObjektspracheObjektsprache ist jene Sprache, die der Gegenstand (das Objekt) der Untersuchung ist – in unserem Fall also die logische Sprache. Die MetaspracheMetasprache ist diejenige Sprache, in der über die Objektsprache gesprochen wird, mit anderen Worten die Sprache, in der die „Forschungsergebnisse“ ausgedrückt werden. In unserem Fall handelt es sich bei der Metasprache um die deutsche Sprache. Bei der Untersuchung einer natürlichen Sprache können Objekt- und Metasprache zusammenfallen; so ist es ohne weiteres möglich (und trägt sich auch oft zu), dass eine Grammatik der englischen Sprache selbst in Englisch verfasst ist.
Als Syntax Syntax, Morphologie wird die Lehre von der „Form“ einer natürlichen oder künstlichen Sprache bezeichnet. Syntax beschäftigt sich zum Beispiel mit der Frage, wie die Wörter (allgemeiner: Bausteine) einer Sprache angeordnet werden müssen, damit Sätze entstehen. Anstelle des Wortes „Syntax“ wird bei einer logischen Sprache auch das Wort „Morphologie“ gebraucht.
Semantik Semantik ist die Lehre von der Bedeutung einer Sprache. Sie untersucht insbesondere, welche Bedeutung die einzelnen Bausteine einer Sprache und welche Bedeutung Sätze haben, die aus diesen Bausteinen geformt werden.
Pragmatik Pragmatik untersucht, welche Wirkung die Bausteine und Sätze einer Sprache auf den Hörer bzw. Leser haben. Die Pragmatik wird üblicherweise nicht zur formalen Logik gezählt und kommt in diesem Skriptum nicht zur Sprache.
Die Bausteine Bausteine einer Sprache sind jene „Dinge“, aus denen die Sätze dieser Sprache zusammengesetzt sind.
Als Bausteine einer natürlichen Sprache kann man ihre Wörter und Interpunktionszeichen betrachten. Eine andere Möglichkeit besteht darin, die Wörter ihrerseits als zusammengesetzt zu betrachten und nicht sie, sondern die Buchstaben und Interpunktionszeichen als Bausteine zu betrachten.
In einer künstlichen logischen Sprache stellt sich die Frage, ob Wörter oder Buchstaben als ihre Bausteine betrachtet werden sollen, in der Regel nicht, weil „Wörter“ und „Buchstaben“ zusammenfallen.
Formationsregeln Formationsregeln geben an, wie die Bausteine einer Sprache angeordnet werden müssen, damit Sätze dieser Sprache entstehen.
Die Linguistik (Sprachwissenschaft) Linguistik beschäftigt sich unter anderem damit, Formationsregeln für natürliche Sprachen aufzustellen. Es ist bis heute nicht gelungen, irgendeine natürliche Sprache durch Formationsregeln vollständig zu beschreiben.
TransformationsregelnTransformationsregeln beschreiben, auf welche Weise Sätze umgeformt werden dürfen, ohne dass sie bestimmte Eigenschaften, die sie vor der Umformung hatten, verlieren. Im Fall der hier vorgestellten logischen Sprache sind die Transformationsregeln so gewählt, dass bestehende Sätze nur zu solchen Sätzen umgeformt werden können, die aus den bestehenden Sätzen folgen.
Ein Kalkül Kalkül ist ein System, das die Syntax einer logischen Sprache festlegt:
Syntax beschäftigt sich mit der „Form“ einer Sprache, gibt also an, welche Zeichen („Bausteine“) in der Sprache vorkommen, wie diese Zeichen angeordnet werden dürfen, damit Sätze entstehen, und wie Sätze umgeformt werden können, ohne dass sie bestimmte Eigenschaften verlieren, die sie vor der Umformung hatten.
Ein System, das die Syntax einer formalen Sprache vollständig beschreibt, heißt Kalkül. Im vorliegenden Skriptum wird wie zumeist auch in der Vorlesung einKalkül des natürlichen SchließensNatürliches Schließen1, ein Regelkalkül, behandelt. Ein solcher Kalkül zeichnet sich dadurch aus, dass es etliche Transformationsregeln, aber keine Axiome gibt. Im Gegensatz dazu gibt es z.B. axiomatische Kalküle und Baumkalküle. Ein Kalkül des natürlichen Schließens kommt dem natürlichen Schließen näher als ein axiomatischer Kalkül (daher der Name) und ist üblicherweise leichter zu handhaben als letzterer.
Die Bausteine der in diesem Skriptum vorgestellten logischen Sprache werden in Kapitel 3.2 (Seite §) vollständig aufgezählt. Die zulässigen Sätze können nicht aufgelistet werden, weil es ihrer unendlich viele gibt. Statt einer Aufzählung gibt es Regeln, die beschreiben, wie gültige Sätze gebildet werden. Diese Regeln heißen Formationsregeln und werden in Kapitel 3.3 (Seite §) dargestellt. Zuletzt gibt es die Transformationsregeln, die in Kapitel 3.6 (Seite §) zur Sprache kommen. Sie erlauben es, einen Satz so umzuformen, dass aus ihm ein anderer Satz entsteht, der aus dem ersten Satz folgt.
Mit Hilfe der Transformationsregeln ist es möglich, ein Argument, das zuvor in die logische Sprache übersetzt wurde, auf seine Gültigkeit hin zu untersuchen: Wenn es möglich ist, aus den Prämissen durch (mehrfache) Anwendung der Transformationsregeln die Konklusion herzuleiten, dann ist das Argument syntaktisch gültig.
Es gibt verschiedene Konventionen, eine solche Herleitung oder Ableitung Ableitung, Herleitung aufzuschreiben. Im vorliegenden Text wird folgendermaßen vorgegangen:
Jeder Satz der Ableitung (d.h. jede Prämisse, die Konklusion und alle Sätze, die in Zwischenschritten gewonnen wurden) wird in eine eigene Zeile geschrieben und erhält eine fortlaufende Nummer, die in Klammern gesetzt wird:
| (1) | erster Satz | ||
| (2) | zweiter Satz | ||
| und so weiter |
Links der Zeilennummer jedes Satzes werden die Nummern aller Annahmen aufgezählt, von denen der Satz abhängt (d.h. auf denen er beruht, d.h. aus denen er folgt). Diese Aufzählung nennt man daher die Prämissenliste Prämissenliste der aktuellen Zeile. Nehmen wir an, in einer (informellen) Ableitung trete folgende Zeile auf:
| 1,4,7 | (10) | Alles ist eitel. |
Die Nummer dieser Zeile ist 10, und ihre Prämissenliste lautet „1,4,7“. In Worten bedeutet das nichts anderes als: Satz (10), also der Satz „Alles ist eitel“, folgt aus den Annahmen (1), (4) und (7).
Zur Rechten jedes Satzes werden (a) die Nummern derjenigen Sätze genannt, aus denen, und (b) die Regel, mit deren Hilfe der Satz gewonnen wurde; dazu im Folgenden mehr.
Eine Ableitung, deren letzte Zeile von keiner Annahme abhängt, deren letzte Zeile also eine leere Prämissenliste hat, heißt BeweisBeweis. Der Satz in der letzten Zeile eines Beweises heißt Theorem.Theorem
| (10) | Es regnet, oder es regnet nicht. |
| Die leere Prämissenliste sagt aus: | |
| „Die Zeile (10) gilt voraussetzungslos“. |
Um die syntaktische Gültigkeit eines Arguments auszudrücken, verwendet man das Zeichen ⊢⊢. Man schreibt die Prämissen durch Beistriche getrennt zu seiner Linken, die Konklusion zu seiner Rechten. Ein durchgestrichenes Folgerungszeichen, ⁄⊢, bedeutet, dass das Argument nicht syntaktisch gültig ist.
Das Bikonditional hat in unserer logischen Sprache eine Sonderstellung; wir wollen es nicht als Teil der Sprache betrachten, sondern einen Ausdruck der Form (φ ↔ ψ) (wobei φ und ψ irgendwelche Sätze sind) als eine bloße Abkürzung für den längeren Ausdruck ((φ → ψ) ∧ (ψ → φ)). Was dieser Ausdruck bedeutet, wird erst im Folgenden klar.
Die folgenden Produktionsregeln, die in beliebiger Reihenfolge und beliebig oft angewandt werden dürfen, erzeugen alle Sätze der hier behandelten logischen Sprache.
Jeder Prädikatbuchstabe, der von mindestens null Individuenkonstanten oder beliebigen Namen gefolgt wird, ist ein Satz.
Die Anzahl der Individuenkonstanten und beliebigen Namen, die einem Prädikatbuchstaben folgen, ist seine StelligkeitStelligkeit (engl. arity). Prädikatbuchstaben müssen einheitlich verwendet werden, d.h. ein Prädikatbuchstabe darf nicht an unterschiedlichen Stellen verschiedene Stelligkeit haben.
Ein nullstelliger Prädikatbuchstabe wird auch Satzbuchstabe Satzbuchstabe genannt. Aussagenlogik In der Aussagenlogik treten nur nullstellige Prädikatbuchstaben auf.
Wenn zwei beliebige Gebilde φ und ψ6 Sätze sind, dann sind folgende Gebilde ebenfalls Sätze:
Mit anderen Worten: Aus zwei bestehenden Sätzen kann man einen neuen Satz erzeugen, indem man die beiden Sätze nebeneinanderschreibt, zwischen die beiden eines der Zeichen „∧“, „∨“ und „→“ setzt und das so entstandene Gebilde in Klammern setzt.
Wenn ein beliebiges Gebilde φ ein Satz ist, dann ist ¬φ ebenfalls ein Satz.
Mit anderen Worten: Aus einem bestehenden Satz kann man einen neuen Satz erzeugen, indem man ihm das Zeichen „¬“ voranstellt.
Wenn ι eine Individuenkonstante, α eine Individuenvariable und φ(ι) ein Satz ist, in dem die Individuenkonstante ι mindestens einmal vorkommt und in dem die Individuenvariable α nicht vorkommt, dann sind folgende Gebilde ebenfalls Sätze:
Dabei bedeutet φ( ι α), dass im Satz φ mindestens ein Vorkommnis der Individuenkonstante ι durch die Individuenvariable α ersetzt wurde.
Etwas weniger exakt, aber bildlicher: Aus einem bestehenden Satz, in dem eine bestimmte Individuenkonstante, z.B. a, vorkommt, kann man einen neuen Satz erzeugen, indem man (a) die Individuenkonstante an mindestens einer Stelle durch eine Individuenvariable ersetzt, die in diesem Satz nicht auftritt, und (b) eines der Zeichen „∧ “ und „∨ “, gefolgt von der verwendeten Variable, vor den Satz schreibt.
Wenn ι und τ (nicht notwendigerweise unterschiedliche) Individuenkonstanten oder beliebige Namen sind, dann ist ι = τ ein Satz.
Die von den vorangehenden Formationsregeln gebildeten Sätze liegen in Peano-Russell-NotationPeano-Russell-Notation8 oder Infix-Notation vor. Diese Notation ist eine KlammerschreibweiseKlammerschreibweise, weil sie Mehrdeutigkeiten erlaubt, die nur mit Klammern aufgelöst werden können; z.B. sieht man der Zeichenfolge P → Q∧R nicht an, ob damit der Satz P → (Q∧R) oder der Satz (P → Q) ∧R gemeint ist. Unsere Formationsregeln entschärfen dieses Problem insoferne, als sie uns zwingen, stets Klammern zu setzen. Dennoch werden längere Sätze in dieser Notation sehr rasch unübersichtlich – mit diesem Problem setzen sich die Kapitel 3.4 und 3.5 näher auseinander.
Es ist üblich, zur Verringerung der Schreibarbeit die äußersten Klammern eines Satzes (und nur diese) wegzulassen, also z.B. statt ((P ∧ Q) → Q) ganz einfach (P ∧ Q) → Q zu schreiben. Obwohl das strenggenommen eine Verletzung der Formationsregeln ist, wird das auch in diesem Skriptum meist so gehandhabt.
In der Literatur kursieren zahlreiche weitere miteinander unverträgliche „Vereinfachungssysteme“, mit denen sich die Anzahl der Klammern weiter verringern lässt. Gerade für Anfänger haben sie die gegenteilige Wirkung, sodass ich davon absehe, näher auf eines von ihnen einzugehen. Sobald der Leser mit der logischen Sprache in der hier dargebotenen Form gut vertraut ist, wird es ihm sehr leicht fallen, sich in der weiterführenden Literatur mit anderen Konventionen vertraut zu machen.
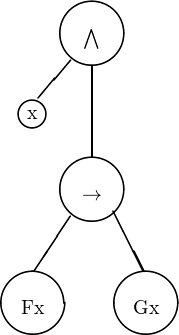
SyntaxbäumeSyntaxbaum (Ausdrucksbaum, engl. parse tree) sind eine einfache Methode, darzustellen, wie ein Satz mittels der Formationsregeln des vorangehenden Kapitels erzeugt worden ist. Die grundlegende Gestalt eines Baums ist in Abbildung 3.1 (Seite §) dargestellt. Die Kreise in einem Baum heißen KnotenKnoten, die Linien KantenKante, Zweige oder Äste. Der oberste Knoten ist die WurzelWurzel des Baums. Knoten, von denen keine Zweige weglaufen, werden BlätterBlatt oder Endknoten genannt.
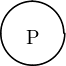
Zum Syntaxbaum wird ein Baum dadurch, dass er den Entstehungsweg eines Satzes ausdrückt. Gehen wir vom Satzbuchstaben P aus; er ist gemäß Regel 3.3 ein Satz. Abbildung 3.2 (Seite §) zeigt einen Knoten, der diesen Satzbuchstaben wiedergibt.
Dieser Knoten ist zugleich der Baum für den (kurzen) Satz P.
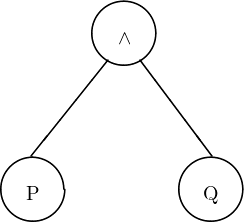
Die Formationsregel 3.3 erlaubt es uns, zwei bestehende Sätze zu einem neuen zu verbinden, indem wir eines der zweistelligen Konnektive zwischen die beiden schreiben. Wählen wir als Konnektiv das Und und als zweiten Satz den Satzbuchstaben Q, dann entsteht der Satz (P ∧Q). Dieser Satz ist eine Konjunktion; in die Wurzel des Syntaxbaums wird daher das Und geschrieben. Da es sich um ein zweistelliges Konnektiv handelt, laufen von der Wurzel zwei Kanten weg. Die linke Kante läuft zu einem Teilbaum hin, der das linke Konjunkt darstellt; da dieses ein einfacher Satzbuchstabe ist, ist der linke Teilbaum ein einfacher Knoten. Ebenso verhält es sich mit dem rechten Konjunkt. Den kompletten Baum zeigt Abbildung 3.3 (Seite §).
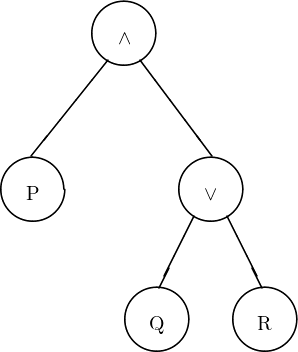
Der Baum für den Satz (P ∧ (Q ∨ R)) ist etwas umfangreicher. Da auch dieser Satz eine Konjunktion ist, wird die Wurzel mit dem Und beschriftet. Wie im vorangehenden Beispiel ist das linke Konjunkt ein Satzbuchstabe, wird also durch einen einfachen Knoten dargestellt. Das rechte Konjunkt ist allerdings ein zusammengesetzter Satz, nämlich eine Disjunktion. Der rechte von der Wurzel ausgehende Knoten verläuft daher zu einem mit dem Oder beschrifteten Knoten. Vom Oder-Knoten laufen seinerseits zwei Kanten weg, weil auch das Oder ein zweistelliges Konnektiv ist. Jede dieser beiden Kanten verläuft zu einem Teilbaum, der das linke bzw. das rechte Disjunkt wiedergibt. Der vollständige Baum ist in Abbildung 3.4 (Seite §) dargestellt.
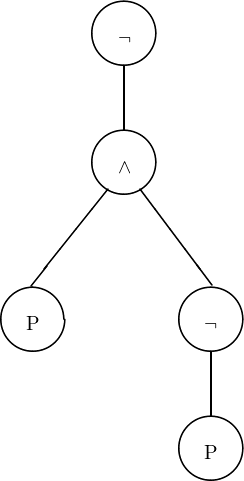
Von einem Knoten für ein einstelliges Konnektiv läuft nur ein Zweig weg, was für den Satz ¬(P ∧¬P) in Abbildung 3.5 (Seite §) gezeigt wird.
Bei Quantoren geht man gerne so vor, dass man die Individuenvariable, die neben dem Quantor steht, unter die eine und den quantifizierten Satz unter die andere Kante des Knotens schreibt. Satz ∧ x(Fx → Gx) ist in Abbildung 3.6 (Seite §) dargestellt.
Bäume im Allgemeinen und Syntaxbäume im Besonderen spielen in der Informatik eine sehr große Rolle. Hat man sich erst einmal an sie gewöhnt, wird man sie als eine übersichtliche Darstellung von Aussagen schätzen, der man die Struktur eines Satzes sofort ansieht und die dennoch ohne Klammern auskommt.
Der große Nachteil der verbreiteten Peano-Russell-Notation ist die Notwendigkeit, viele Klammern zu verwenden, die längere Sätze schwer lesbar machen. Die Syntaxbäume von Kapitel 3.4 sind zwar frei von Klammern und geben die Struktur eines Satzes sehr deutlich wieder, brauchen aber recht viel Platz.
Lange vor dem Aufkommen von Syntaxbäumen publizierte der polnische Logiker und Philosoph Jan Łukasiewicz (1878-1956) im Jahr 1930 eine Schreibweise, die ohne Klammern auskommt.9 In dieser polnischen oder Präfix-Notation werden grundsätzlich Kleinbuchstaben als Satzbuchstaben verwendet. Es gibt folgende Konnektive:
In der polnischen Notation wird stets zuerst das Konnektiv und unmittelbar danach der dazugehörende Satz bzw. die dazugehörenden Sätze geschrieben.
| Peano-Russell-Notation | Polnische Notation |
| (P ∧ Q) | Kpq |
| (P ∧ (Q ∨ R)) | KpAqr |
| ((P ∧ Q) ∨ R) | AKpqr |
| ((P → Q) ∨ (Q → P)) | ACpqCqp |
Ein einfaches mechanisches Verfahren, um zu überprüfen, ob eine beliebige Zeichenfolge ein wohlgeformter Satz in polnischer Notation ist, entdeckte 1950 Helmut Angstl.
Eine leichte Modifikation der polnischen Notation ist die umgekehrte polnische NotationUPN (UPN, Postfix-Notation), bei der das Konnektiv nicht vor, sondern nach die verbundenen Sätze geschrieben wird. Eingeführt wurde die umgekehrte polnische Notation von der Firma Hewlett-Packard als damals einzige Möglichkeit, komplexe Formeln einfach in Taschenrechner einzugeben. In einigen Modellen lebt diese Notation bis heute.
Die Transformationsregeln bestimmen, wie ein Satz umgeformt (transformiert) werden darf, ohne dass er die Eigenschaft zuzutreffen, so er diese besaß, verliert.
Allgemein gibt es für jedes Konnektiv und für jeden Quantor eine Einführungs- und eine Beseitigungsregel. Eine EinführungsregelEinführungsregel erlaubt es, auf einen Satz zu schließen, in dem das betreffende Konnektiv oder der Quantor vorkommt. Eine Beseitigungsregel erlaubt es, aus einem Satz zu schließen, der das betreffende Konnektiv oder den Quantor enthält.
Jeder beliebige Satz darf angenommen werden. Eine Annahme beruht auf sich selbst.
| 1 | (1) | P → Q | A |
Die laufende Nummer der Zeile ist 1. Da eine Annahme nur von sich selbst abhängt, scheint in der Prämissenliste nur Satz 1 selbst auf. Wörtlich bedeutet das: „Es ist erwiesen, dass Satz (1) unter der Voraussetzung gilt, dass Satz (1) gilt“ – eine nicht sehr spektakuläre Feststellung.
Gewonnen wurde der Satz mit Hilfe der Regel der Annahme, worauf das „A“ am rechten Zeilenrand hinweisen soll.
| Angenommen, Sokrates sei unsterblich. |
Wenn zwei Sätze zutreffen, trifft auch die Konjunktion beider zu.
φ
ψ
__________
(φ ∧ ψ)
beziehungsweise
φ
ψ
__________
(ψ ∧ φ)
Das Ergebnis einer Anwendung der Regel der Und-Einführung beruht auf allen Annahmen, auf denen die beiden Sätze beruhen, auf die die Regel angewandt wurde.
| 1 | (1) | P | A |
| 2 | (2) | Q | A |
| 1,2 | (3) | P ∧ Q | 1,2 ∧ E |
| (1) | Logik ist uninteressant. | ||
| (2) | Die Sonne scheint. | ||
| (3) | Also ist Logik uninteressant, und die Sonne scheint. |
Wenn die Konjunktion beider Sätze gültig ist, dann ist jeder der beiden Sätze auch für sich allein gültig.
(φ ∧ ψ)
_____
φ
beziehungsweise
(φ ∧ ψ)
_____
ψ
Das Ergebnis einer Anwendung der Regel der Und-Beseitigung beruht auf allen Annahmen, auf denen der Satz, auf den die Regel angewandt wurde, beruht.
| 1 | (1) | P ∧ Q | A |
| 1 | (2) | P | 1 ∧ B |
| (1) | Es regnet, und Logik ist interessant. | ||
| (2) | Also ist Logik interessant. |
Wenn ein Satz gültig ist, dann ist jede Disjunktion gültig, deren Disjunkt dieser Satz ist.
φ
__________
φ ∨ ψ
beziehungsweise
φ
__________
ψ ∨ φ
Das Ergebnis einer Anwendung der Regel der Oder-Einführung beruht auf allen Annahmen, auf denen der Satz beruht, auf den die Regel angewandt wurde.
| 1 | (1) | ∧ x(Fx → Gx) | A |
| 1 | (2) | ∧ x(Fx → Gx) ∨ Q | 1 ∨ E |
| (1) | Es regnet. | ||
| (2) | Also regnet es, oder die Sonne scheint, oder beides. |
Wenn ein Satz aus jedem Disjunkt einer Disjunktion folgt, dann folgt er aus der Disjunktion erst recht.
| (a) | φ ∨ ψ |
| (b) | [φ] |
 |
|
| (c) | χ |
| (d) | [ψ] |
 |
|
| (e) | χ |
| (f) | χ |
Die mit (a) gekennzeichnete Disjunktion besteht aus den Disjunkten φ und ψ. Das erste Disjunkt, φ, wird in der mit (b) gekennzeichneten Zeile angenommen (deshalb die eckigen Klammern). Aus dieser Annahme wird die gewünschte Konklusion, χ, die in Zeile (c) aufscheint, hergeleitet. Anschließend wird in Zeile (d) das zweite Disjunkt, ψ, angenommen. Auch aus ihm wird die gewünschte Konklusion, χ, hergeleitet. Nachdem all das geschehen ist, steht fest, dass die gewünschte Konklusion, χ, aus der gesamten Disjunktion erst recht folgt. Sie wird daher in der Ergebniszeile (f) ein weiteres Mal angeführt.
Zitiert werden in Zeile (f) folgende Zeilen:
Das Ergebnis einer Anwendung der Regel der Oder-Beseitigung hängt von folgenden Zeilen ab:
| 1 | (1) | (P ∧ Q) ∨ (P ∧ R) | A | (a) |
| 2 | (2) | P ∧ Q | A | (b) |
| 2 | (3) | P | 2 ∧ B | (c) |
| 4 | (4) | P ∧ R | A | (d) |
| 4 | (5) | P | 4 ∧ B | (e) |
| 1 | (6) | P | 1,2,3,4,5 ∨ B |
Die Disjunktion (a) lautet (P ∧Q) ∨ (P ∧R). Ihr erstes Disjunkt, (P ∧Q), wird in Zeile (b) – im Beispiel (2) – angenommen. In einem einzigen Schritt gelingt es, daraus die gewünschte Konklusion (c) – im Beispiel (3) – herzuleiten. Das ist schön.
Danach wird das zweite Disjunkt, (P ∧ R), in Zeile (d) – im Beispiel (4) – angenommen. Auch aus ihm kann in einem einzigen Schritt die gewünschte Konklusion (e) – im Beispiel (5) – hergeleitet werden.
Nun steht fest, dass die gewünschte Konklusion aus der Disjunktion folgt; erstere wird daher in der Ergebniszeile – im Beispiel (6) – noch einmal angeschrieben.
| Es regnet, und ich gehe ins Kino; oder |
| es ist schönes Wetter, und ich gehe ins Kino. |
| Also gehe ich in jedem der beiden Fälle ins Kino. |
Inhaltlich motiviert sich die Regel der Oder-Beseitigung wie folgt:
Eine Disjunktion besagt, dass mindestens eines ihrer beiden Disjunkte zutrifft. Leider sieht man einer Disjunktion nicht an, welches Disjunkt das zutreffende ist. Um aus einer Disjunktion etwas schließen zu können, müssen wir daher beide Fälle berücksichtigen; diese Fallunterscheidung nimmt unsere Oder-Beseitigung vor, indem sie zuerst den einen Fall ansetzt (das erste Disjunkt trifft zu) und anschließend den zweiten Fall (das zweite Disjunkt trifft zu). Wenn in jedem der beiden Fälle dasselbe bewiesen werden kann (die „gewünschte Konklusion“), dann gilt das Bewiesene unbedingt: Denn mehr als die beiden untersuchten Fälle gibt es nicht, und was in jedem Fall gilt, das gilt jedenfalls.11
Wenn es gelingt, aus einer Annahme φ und allfälligen Zusatzannahmen einen Satz ψ herzuleiten, so folgt aus den Zusatzannahmen alleine (d.h. ohne φ) der Satz (φ → ψ).12
| [φ] |
 |
| ψ |
| (φ → ψ) |
Zitiert wird sowohl die Zeile, in der das Antecedens φ des Konditionals angenommen wird, als auch die Zeile, in der das aus dem Antecedens hergeleitete Konsequens, ψ, aufscheint.
Das Ergebnis einer Anwendung der Regel der Pfeil-Einführung hängt von allen Annahmen ab, von denen das Konsequens, ψ, in seiner Herleitung aus der Annahme des Antecedens, φ, abhängt, außer von φ selbst.
| 1 | (1) | P ∧ Q | A |
| 1 | (2) | Q | 1 ∧ B |
| (3) | (P ∧ Q) → Q | 1,2 → E |
Wenn eine hinreichende Bedingung für einen Sachverhalt erfüllt ist, besteht dieser.
| (φ → ψ) |
| φ |
| ψ |
Das Ergebnis einer Anwendung der Regel der Pfeil-Beseitigung beruht auf allen Annahmen, auf denen die Sätze beruhen, auf die die Regel angewandt wurde.
| 1 | (1) | (P → Q) | A |
| 2 | (2) | P | A |
| 1,2 | (3) | Q | 1,2 → B |
| Wenn es jetzt hier regnet, dann ist |
| diese Straße jetzt nass. |
| Es regnet jetzt hier. |
| Also ist diese Straße jetzt nass. |
Eine Annahme, die zu einem Widerspruch führt, ist fehlerhaft und darf verneint werden.
Anmerkung: Ein WiderspruchWiderspruch ist ein Satz der Form (φ ∧¬φ).
| [φ] |
 |
| (ψ ∧¬ψ) |
| ¬φ |
Zitiert wird die Annahme, die zum Widerspruch geführt hat, und der Widerspruch selbst.
Das Ergebnis ¬φ einer Anwendung der Negationseinführung hängt von allen Annahmen ab, von denen der Widerspruch abhängt, außer der Annahme, die für den Widerspruch verantwortlich gemacht wird.
| 1 | (1) | P → Q | A |
| 2 | (2) | ¬Q | A |
| 3 | (3) | P | A |
| 1,3 | (4) | Q | 1,3 → B |
| 1,2,3 | (5) | Q ∧¬Q | 2,4 ∧ E |
| 1,2 | (6) | ¬P | 3,5¬E |
In diesem Beispiel tritt in der Zeile (5) ein Widerspruch auf, Q ∧¬Q. Dieser Widerspruch hängt – das sagt uns seine Prämissenliste – von den Annahmen (1), (2) und (3) ab. Da ein Widerspruch nicht zutreffen kann, muss eine der Annahmen, die zu ihm geführt haben, unzutreffend sein. Welche Annahme das ist, bleibt dem Urteil der Schließenden überlassen; in unserem Beispiel hat sie sich dafür entschieden, Annahme (3) als den Übeltäter zu identifizieren und folglich zu verneinen; das Verneinen geschieht in Zeile (6). Die schuldige Annahme, (3), scheint auch nicht mehr in der Prämissenliste von Zeile (6) auf.
Was auch immer nicht nicht der Fall ist, ist der Fall.
| ¬¬φ |
| φ |
Die Regel der Nicht-Nicht-Beseitigung ist theologisch und philosophisch nicht unumstritten. Sie ist unbedingt erforderlich für den Beweis des tertium non datur (⊢ p ∨¬p).
Wenn sich zeigen lässt, dass ein Satz für ein völlig beliebig gewähltes Individuum gilt, dann gilt er für jedes Individuum.
| φ(ι) |
| ∧ αφ( ι α) |
Hierbei ist ι ein beliebiger Name und α eine Individuenvariable. φ(ι) ist ein Satz, in dem ι vorkommt und in dem α nicht vorkommt. φ( ι α) ist der Satz, der entsteht, wenn jedes Vorkommnis von ι in φ(ι) durch α ersetzt wird.
Das Ergebnis einer Anwendung der Allquantor-Einführung hängt von allen Annahmen ab, von denen der Satz abhängt, auf den die Regel angewandt wurde.
| 1 | (1) | ∧ x(Fx → Gx) | A |
| 2 | (2) | ∧ xFx | A |
| 1 | (3) | Fu → Gu | 1∧ B |
| 2 | (4) | Fu | 2∧ B |
| 1,2 | (5) | Gu | 3,4 → B |
| 1,2 | (6) | ∧ xGx | 5∧ E |
Das Ergebnis der ∧ E, Zeile (6), hängt ab von den Annahmen (1) und (2). In keiner von beiden tritt das beliebige Individuum u auf, daher ist der Schritt der ∧ E zulässig.
Wenn eine Behauptung auf jedes Individuum zutrifft, dann trifft sie auf ein einzelnes konkretes Individuum „erst recht“ zu.
| ∧ αφ(α) |
| φ(α ι ) |
α ist eine Individuenvariable, ι ist eine Individuenkonstante oder ein beliebiger Name und φ(α) ein Satz, in dem α vorkommt. φ(α ι ) ist der Satz, der entsteht, wenn in φ(α) jedes Vorkommnis von α durch ι ersetzt wird.
| 1 | (1) | ∧ xFx | A |
| 1 | (2) | Fa | 1∧ B |
| Alles ist eitel. |
| Also ist Logik eitel. |
Die Allquantor-Beseitigung hat eine gewisse Verwandtschaft zur Und-Beseitigung. Wenn es nur endlich viele Dinge gibt, dann ist eine Allaussage der Form „Alle Individuen sind sterblich“ äquivalent zur Aussage „Das erste Individuum ist sterblich, und das zweite Individuum ist sterblich, und das dritte Individuum ist sterblich, und das vierte Individuum ist sterblich, und das fünfte Individuum ist sterblich, und das sechste Individuum ist sterblich, und das siebente Individuum ist sterblich, und das achte Individuum ist sterblich, und das neunte Individuum ist sterblich, und das zehnte Individuum ist sterblich, und das elfte Individuum ist sterblich, und das zwölfte Individuum ist sterblich, …, und das zweiundvierzigste Individuum ist sterblich, …, und das letzte Individuum ist auch sterblich“. Diese Aussage ist eine Konjunktion. Aus ihr mittels einer Und-Beseitigung zu schließen ist dasselbe wie aus der Allaussage mit der Allquantor-Beseitigung zu schließen.
Die Äquivalenz zwischen einer Allaussage und einer Konjunktion geht im allgemeinen Fall, in dem es unendlich viele Individuen geben kann oder in dem man gar nicht weiß, wieviele Individuen es nun tatsächlich gibt, verloren, denn weder kann man eine unendlich lange Konjunktion äußern, noch kann man eine Konjunktion aufschreiben, ohne zu wissen, wieviele Konjunkte sie hat. Dennoch sollte man nicht völlig verdrängen, dass es einen Zusammenhang zwischen beiden gibt.
Wenn ein Prädikat auf ein bestimmtes Individuum zutrifft, folgt daraus, dass es auf mindestens ein Individuum zutrifft.
| φ(ι) |
| ∨ αφ( ι α) |
ι ist eine Individuenkonstante oder ein beliebiger Name, α eine Individuenvariable und φ(ι) ein Satz, in dem ι vorkommt. φ( ι α) ist der Satz, der entsteht, wenn in φ(ι) mindestens ein Vorkommnis von ι durch α ersetzt wird.
Das Ergebnis einer Anwendung der Regel der Existenzquantor-Einführung hängt von allen Annahmen ab, von denen der Satz abhängt, auf den die Regel angewandt wurde.
| 1 | (1) | Fa ∧ Ga | A |
| 1 | (2) | ∨ x(Fx ∧ Gx) | 1∨ E |
| Sokrates ist sterblich. |
| Also ist mindestens ein Individuum sterblich. |
Aus einer Existenzbehauptung lässt sich mit Hilfe eines beliebigen Namens schließen. Wenn aus der Annahme, der behauptete Satz treffe auf ein völlig beliebig gewähltes Individuum zu, die gewünschte Konklusion folgt, so folgt sie auch aus der Existenzbehauptung selbst.
Eine Existenzbehauptung sagt aus, dass ein Satz13 φ auf mindestens ein Individuum zutrifft. Sie verrät uns weder, wieviele solche Individuen es gibt, noch, um welche Individuen es sich dabei handelt. Um aus der Existenzbehauptung dennoch etwas schließen zu können, greifen wir willkürlich eines der Individuen, auf die der Satz φ zutrifft, heraus und benennen es mit einem beliebigen Namen – ohne dabei festzulegen oder zu wissen, um welches konkrete Individuum es sich handelt. Wenn es uns gelingt, aus dieser vagen Aussage „Der Satz φ trifft auf das Individuum u zu, ohne dass wir wissen, was u eigentlich ist“ irgendetwas zu schließen, dann folgt es tatsächlich aus der Existenzbehauptung.
| (a) | ∨ αφ(α) | |||
| (b) | [φ(α ι )] | „typisches Disjunkt“ | ||
 | ||||
| (c) | ψ | |||
| (d) | ψ |
α ist eine Individuenvariable, ι ein beliebiger Name und φ(α) ein Satz, in dem α vorkommt. φ(α ι ) ist der Satz, der entsteht, wenn in φ(α) jedes Vorkommnis von α durch ι ersetzt wird.
Bei einer Anwendung der Regel der Existenzquantor-Beseitigung werden folgende Zeilen zitiert:
Das Ergebnis einer Existenzquantor-Beseitigung hängt ab von:
| 1 | (1) | ∨ x(Fx ∧ Gx) | A | (a) |
| 2 | (2) | Fu ∧ Gu | A | (b) |
| 2 | (3) | Fu | 2 ∧ B | |
| 2 | (4) | ∨ xFx | 3∨ E | (c) |
| 1 | (5) | ∨ xFx | 1,2,4∨ B |
So wie die Allquantor-Beseitigung mit der Und-Beseitigung verwandt ist (vgl. Kapitel 3.6.11, Seite §), besteht eine Beziehung zwischen der Existenzquantor-Beseitigung und der Oder-Beseitigung.
Wenn es nur endlich viele Individuen gibt, dann ist eine Existenzaussage äquivalent zu einer Disjunktion.
Da die Disjunkte einer solchen Disjunktion dieselbe Form haben (in obigem Beispiel „…ist ein Nilpferd“) und sich nur darin unterscheiden, von welchem Individuum sie sprechen, wäre es Verschwendung von Arbeitskraft, eine vollständige Oder-Beseitigung auszuführen. Bei der Existenzquantor-Beseitigung wird die Oder-Beseitigung sozusagen nicht für jedes Disjunkt ausgeführt, sondern nur ein einziges Mal für ein einziges Disjunkt, das aber repräsentativ für alle anderen Disjunkte sein muss – das typische Disjunkt. Um ein solches typisches Disjunkt zu erhalten, verwendet man anstelle eines konkreten Namens (im obigen Beispiel a, b oder c) einen beliebigen Namen (z.B. u), der für ein völlig beliebiges Individuum steht.
Dient die Existenzquantor-Beseitigung bei einem endlichen Individuenbereich mehr der Bequemlichkeit (lange Disjunktionen sind unhandlich zu schreiben und zu beseitigen), ist sie im allgemeinen Fall, in dem es unendlich viele Individuen gibt oder in dem die Individuenzahl nicht bekannt ist, unerläßlich: Eine unendlich lange Disjunktion oder eine Disjunktion mit einer unbekannten Zahl von Disjunkten lässt sich nicht aufschreiben und daher erst recht nicht beseitigen. Hier ist ein typisches Disjunkt, das alle Disjunkte der fiktiven unendlich langen Disjunktion vertritt, unerläßlich.
Jede Individuenkonstante bezeichnet genau ein Individuum, und zwar während einer gesamten Ableitung immer dasselbe Individuum. Diesen Sachverhalt darf man aufschreiben, wenn man das für sinnvoll hält:
| ι = ι |
Dabei ist ι irgendeine Individuenkonstante oder ein beliebiger Name.
Das Ergebnis einer Anwendung der Identitätseinführung hängt von keinen Prämissen ab, weil es konstitutives Element der hier entwickelten logischen Sprache ist, dass ein Name während seiner Verwendung seinen Bezug nicht ändert.
| (1) | a = a | = E |
| Leibniz ist Leibniz. |
Wenn zwei Namen denselben Gegenstand bezeichnen, dann können die beiden Namen beliebig gegeneinander ausgetauscht werden. Dieses Prinzip ist bekannt als das Prinzip der Substitution salva veritate14.
| ι = τ |
| φ(ι) |
| φ( ι τ ) |
ι und τ sind (nicht notwendigerweise verschiedene) Individuenkonstanten oder beliebige Namen, φ(ι) ist ein Satz, in dem ι mindestens einmal vorkommt, und φ( ι τ ) ist ein Satz, der entsteht, indem in φ(ι) mindestens ein Vorkommnis von ι durch τ ersetzt wird.
Zitiert wird die Existenzbehauptung und der Satz, in dem die Ersetzung vorgenommen wird.
Das Ergebnis einer Anwendung der Substitution salva veritate hängt von allen Annahmen ab, von denen die Existenzbehauptung abhängt, und von allen Annahmen, von denen φ(ι) abhängt.
| 1 | (1) | a = b | A |
| 2 | (2) | Fa ∧ Ga | A |
| 1,2 | (3) | Fb ∧ Gb | 1,2 = B |
| Platon ist der Autor von Menon. |
| Platon ist ein Philosoph. |
| Also ist der Autor von Menon ein Philosoph. |
Semantik beschäftigt sich mit der Bedeutung der Zeichen und Ausdrücke einer Sprache.
Aussagenlogik enthält daher folgende Elemente:
Das vorliegende Kapitel behandelt die Semantik dieser aussagenlogischen Teile der Prädikatenlogik.
SatzbuchstabenSatzbuchstaben sind nullstellige Prädikatbuchstaben, also Prädikatbuchstaben, denen keine Individuenvariablen und keine beliebigen Namen folgen.
Ein Satzbuchstabe steht für eine beliebige Aussage. So kann der Satzbuchstabe P für „Es regnet“ stehen und der Satzbuchstabe Q für „Logik ist uninteressant“.
Eine der interessantesten Eigenschaften einer Aussage ist ihr WahrheitsgehaltWahrheit. Die hier entwickelte logische Sprache trägt dem Rechnung, indem ihre Semantik den einzelnen Satzbuchstaben WahrheitswerteWahrheitswert zuordnet. Wir verwenden zwei Wahrheitswerte, nämlich wahr (abgekürzt „W“ oder „⊤“) und falsch (abgekürzt „F“ oder „⊥“).
Wenn man jedem Satzbuchstaben aus einer Menge von Satzbuchstaben genau einen Wahrheitswert zuordnet, dann nennt man das – wenig überraschend – Wahrheitswertzuordnung oder kurz ZuordnungZuordnung. Man schreibt eine solche Zuordnung meist auf, indem man die Satzbuchstaben nebeneinanderschreibt, darunter einen Strich zieht und darunter unter jeden Satzbuchstaben den Wahrheitswert setzt, den man ihm zuordnet:
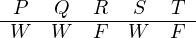
Diese Zuordnung ordnet den Satzbuchstaben P, Q und S den Wahrheitswert wahr und den Satzbuchstaben R und T den Wert falsch zu.
Eine solche Wahrheitswertzuordnung nennt man auch SachverhaltSachverhalt (engl. state of affairs) oder – etwas unglücklich – mögliche Weltmögliche Welt.
Die Bezeichnung Sachverhalt rührt daher, dass die Sätze, indem sie wahr oder falsch sind, einen Sachverhalt beschreiben. Betrachten wir die drei Sätze „Es regnet.“, „Die Sonne scheint“ und „Die Straße ist nass“, und nehmen wir an, dass der erste Satz wahr, der zweite falsch und der dritte wahr ist; dann beschreibt diese Wahrheitswertzuordnung den Sachverhalt, dass es regnet, dass die Straße regennass ist und dass die Sonne nicht scheint.
Der Ausdruck mögliche Welt stammt aus der Philosophie von Leibniz und hat sich als Synonym für „Sachverhalt“ eingebürgert. Wenn man die Wirklichkeit durch Sätze vollständig beschreibt (soferne das überhaupt möglich ist) und diesen Sätzen die ihnen tatsächlich zukommenden Wahrheitswerte zuordnet (soferne das überhaupt möglich ist), dann nennt man diese Wahrheitswertzuordnung tatsächliche Welttatsächliche Welt (engl. actual world).
Das Verhalten der Negation wird den Leser nicht überraschen; sie wechselt einfach den Wahrheitswert des Satzes, auf den sie angewandt wird: Aus einem wahren Satz wird ein falscher und aus einem falschen ein wahrer.
Wenn wir in der deutschen Sprache zwei Sätze mit dem Wort „und“ verbinden, dann meinen wir damit, dass beide Sätze zutreffen. Daher ist es für die Wahrheit einer Konjunktion erforderlich, dass beide Konjunkte wahr sind.
Wenn wir zwei deutsche Sätze mit dem Wort „oder“ (im nichtausschließenden Sinn) verbinden, dann meinen wir damit, dass mindestens einer der beiden Sätze zutrifft. Daher reicht es für die Wahrheit einer Disjunktion, dass ein einziges ihrer Disjunkte wahr ist.
Der Wahrheitswertverlauf des Konditionals ist auf den ersten Blick vielleicht etwas überraschend. Es ist allerdings nicht schwer, seinen Sinn zu verstehen, wenn man einerseits vor Augen hat, dass das Konditional die hinreichende Bedingung (und nur sie) ausdrückt und nichts mit Kausalität oder ähnlich fragwürdigen Dingen zu tun hat, und wenn man andererseits folgender Überlegung folgt:
Nehmen wir an, ich wette mit der Leserin um den Genuss eines Besens, dass es morgen regnen wird. In diesem Fall könnte ich folgende Aussage machen: „Wenn es (morgen) regnet, dann fresse ich einen Besen“. Wir wenden nun unser Augenmerk der Frage zu, ob ich mit meiner Aussage gelogen (die Unwahrheit gesagt) habe oder nicht. Es gibt vier Fälle zu unterscheiden:
In diesem Fall habe ich offensichtlich nicht gelogen, denn ich habe ja meine Zusage, im Fall von Regen einen Besen zu mir zu nehmen, eingehalten. Meine Aussage ist daher wahr.
In diesem Fall habe ich gelogen, denn ich habe meine Zusage nicht eingehalten. Zu lügen heißt, etwas Falsches zu sagen – meine Aussage ist daher falsch.
In diesem Fall habe ich nicht gelogen. Meine Wette sah vor, dass ich im Falle eines Regengusses auf jeden Fall einen Besen fresse. Bei Ausbleiben von Regen steht es mir frei zu tun, was auch immer ich möchte. Da ich nicht gelogen habe, ist meine Aussage wahr.
Auch in diesem letzten Fall habe ich nicht gelogen. Der Verzehr des Besens wäre nur dann meine Pflicht, wenn es tatsächlich regnete; da es nicht regnet, kann ich tun und lassen, was auch immer ich möchte. Ich habe nicht gelogen, also ist meine Aussage wahr.
Diese Aufstellung zeigt sehr klar: Ein Konditional ist nur dann falsch, wenn das Antecedens wahr und das Konsequens falsch ist.
Wahrheitstafeln oder Wahrheitstabellen sind eine tabellarische (daher der Name) und hoffentlich übersichtliche Darstellung aller möglichen Wahrheitswertzuordnungen für die Satzbuchstaben einer Aussage. Es gibt Hinweise darauf, dass bereits die Stoiker Wahrheitstafeln verwendet haben.2 In unserer Zeit wurden Wahrheitstabellen vom amerikanischen Philosophen Charles Sanders Peirce3 neu entdeckt.
Wenn eine Aussage aus n Satzbuchstaben zusammengesetzt ist, dann kann jedem
von ihnen der Wert W oder F zugeordnet werden. Gibt es nur einen einzigen
Satzbuchstaben, z.B. P, dann gibt es nur zwei mögliche Zuordnungen: P _
W und P
F . Mit
jedem weiteren Satzbuchstaben verdoppelt sich die Zahl der Möglichkeiten, weil in
jedem der bisherigen Fälle der neue Satzbuchstabe ebenfalls entweder W oder F
annehmen kann. Allgemein gibt es bei n Satzbuchstaben daher  n-mal,
d.h. 2n verschiedene Wahrheitswertzuordnungen.
n-mal,
d.h. 2n verschiedene Wahrheitswertzuordnungen.
Eine Wahrheitstafel für einen einzigen Satzbuchstaben schreibt man auf, indem man beide möglichen Zuordnungen für diesen Satzbuchstaben untereinander schreibt:
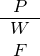
Wenn nun ein weiterer Satzbuchstabe hinzukommt, spaltet man jede der bisherigen Möglichkeiten auf:
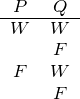
Diesen Schritt kann man beliebig oft wiederholen:
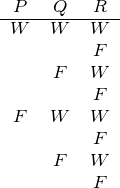
Der Übersichtlichkeit zuliebe füllt man die Leerstellen, die durch das Aufspalten einer Ausgangsmöglichkeit entstanden sind, mit den entsprechenden Wahrheitswerten:

Wenn man am Anfang Schwierigkeiten mit dem Aufschreiben einer Wahrheitstabelle hat, geht man am besten folgendermaßen vor:
Man beginnt mit dem äußersten rechten Satzbuchstaben und schreibt abwechselnd W und F in die jeweils nächste freie Zeile seiner Spalte, bis man 2n (n ist die Zahl der Satzbuchstaben) Zeilen gefüllt hat. Anschließend setzt man fort mit dem linken Nachbarn des Ausgangssatzbuchstaben, nur verdoppelt man bei ihm die Zahl der in jedem Schritt geschriebenen W und F; d.h. statt in eine Zeile ein W und in die nächste Zeile ein F zu schreiben, schreibt man nun in zwei aufeinanderfolgende Zeilen je ein W und danach in die nächsten beiden aufeinanderfolgenden Zeilen je ein F. Damit fährt man fort, bis man bei der letzten Zeile angelangt ist.
Auf diese Weise setzt man, in jeder Zeile die Zahl der aufeinanderfolgenden W bzw. F gegenüber der zuvor geschriebenen Zeile verdoppelnd, fort, bis man alle Spalten gefüllt hat.
Wer Freude an binärer Arithmetik hat, kann sich beim Aufstellen einer Wahrheitstabelle noch leichter behelfen, indem er binär von 2n - 1 auf 0 hinabzählt. Jede der Binärzahlen drückt eine der Zeilen der Wahrheitstabelle aus; jede Binärstelle einer Binärzahl benennt den Wert der entsprechenden Spalte dieser Zeile der Wahrheitstabelle: Lautet sie 1, schreibt man ein W, andernfalls ein F in die entsprechende Spalte.
Um eine Wahrheitstabelle für drei Satzbuchstaben aufzuschreiben, müsste man daher mit 23 - 1 = 7, binär 111, beginnen. Die dezimalen und binären Zahlen sowie die entsprechenden Zeilen der Wahrheitstafel lauten wie folgt:

Üblicherweise schreibt man eine Wahrheitstafel nicht nur zum Vergnügen auf, sondern als Hilfe, um den Wahrheitswertverlauf eines Satzes verfolgen zu können. Betrachten wir als Beispiel den Satz P ∧ Q. Da dieser Satz nur zwei Satzbuchstaben enthält, gibt es 22, also vier verschiedene Zuordnungen von Wahrheitswerten zu diesen Satzbuchstaben. Wir stellen eine Wahrheitstabelle auf:
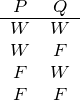
Da uns der Werteverlauf für den Satz P ∧Q interessiert, fügen wir unserer Tabelle für ihn eine weitere Spalte hinzu:
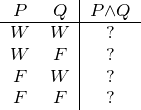
An die Stelle jedes Fragezeichens wollen wir den Wahrheitswert schreiben, den der Satz P ∧ Q für die in der betroffenen Zeile genannte Zuordnung annimmt.
Die erste Zeile der Wahrheitstabelle drückt die Zuordnung P _ W Q W aus. Nach der Definition in Kapitel 4.1.2 (Seite §) ist eine Konjunktion wahr, wenn beide Konjunkte wahr sind. Wir können damit die erste Zeile ergänzen:
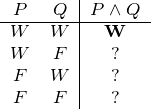
Da nach der Definition in Kapitel 4.1.2 eine Konjunktion in allen anderen Fällen falsch ist, fällt es uns nicht schwer, die Tabelle fertigzustellen:
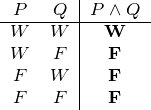
Nach dieser Vorbereitung sind wir in der Lage, für alle Konnektive unserer logischen Sprache Wahrheitstafeln aufzuschreiben:
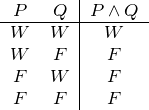
Konjunktion
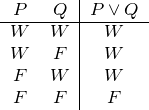
Disjunktion
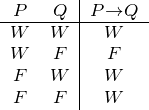
Konditional
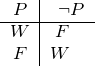
Negation
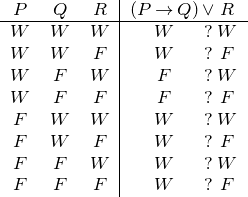
Je komplexerkomplexe Sätze ein Satz ist, desto mehr Arbeit bedeutet es, für ihn eine Wahrheitstafel aufzustellen. Versuchen wir unser Glück an (P → Q) ∨R. Dieser Satz ist eine Disjunktion; das linke Disjunkt ist das Konditional P → Q, das rechte Disjunkt der Satzbuchstabe R. Da in diesem Satz drei Satzbuchstaben auftreten, wird die Wahrheitstabelle 23, also acht Zeilen umfassen:

Um die Wahrheitstabelle für die Disjunktion bilden zu können, müssen wir den Wahrheitswert des linken und den des rechten Disjunkts kennen. Das rechte Disjunkt ist der Satzbuchstabe R; sein Wahrheitswert steht bereits in der R-Spalte. Um die Übersicht nicht zu verlieren, schreiben wir den Wert dennoch unter das rechte Disjunkt:

Diese Information reicht noch nicht aus, um den Wahrheitswert der Disjunktion zu berechnen; wir benötigen noch den Wahrheitswert des linken Disjunkts, also des Konditionals P → Q. Um ihn zu errechnen, benötigen wir Kenntnis der Wahrheitswerte von Antecedens und Konsequens. Da beide Satzbuchstaben sind, können wir ihren Wahrheitswert sofort anschreiben:

Mittels der Definition des Konditionals (Kapitel 4.1.2, Seite §) können wir nun den Wahrheitswertverlauf des linken Disjunkts, d.h. des Konditionals P → Q, errechnen:

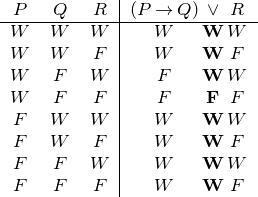
Ehe wir den Wahrheitswert der Disjunktion berechnen, lassen wir zur besseren Übersicht die Spalten mit den Zwischenergebnissen wieder weg:
Da wir nun den Werteverlauf sowohl des linken als auch des rechten Disjunkts kennen, können wir den der Disjunktion ausrechnen:
In der Theorie schreibt man, sobald man ein wenig Übung hat, nicht mehr alle Zwischenergebnisse auf; man sollte dabei aber nicht zu weit gehen, weil man leichter die Übersicht verliert, als man vielleicht den Eindruck hat. In der Praxis schreibt man, sobald man ein wenig Übung hat, überhaupt keine Wahrheitstafeln mehr auf. Diese mechanische und fehleranfällige Arbeit nimmt einem mühelos jeder Computer ab.
Ein Satz, der ungeachtet der Wahrheitswerte der in ihm vorkommenden Satzbuchstaben immer wahr ist, heißt TautologieTautologie.
Eine Tautologie ist z.B. der Satz (P ∧ Q) → Q:
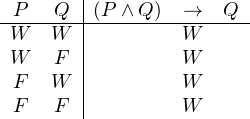
Die in diesem Skriptum behandelte Sprache umfasst die Konnektive ¬, ∧, ∨ und →. Unsere Semantik, die jedem Satzbuchstaben einen der Werte W und F zuordnet, erlaubt viel mehr Konnektive. Dieses Kapitel beschäftigt sich mit der Frage, welche und wieviele Konnektive es geben könnte, ob sie alle in irgendeiner Hinsicht sinnvoll sind oder nicht und ob es einen Grund gibt, warum sich unsere logische Sprache auf die genannten Konnektive beschränkt.
Beginnen wir mit den einstelligen Konnektiven, d.h. mit jenen Konnektiven, die mit einem einzigen Satz verbunden sind. Hier kennen wir nur die Negation, ¬. Sie hat die Wahrheitstafel
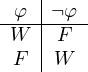
Gibt es einstellige Konnektive, die eine andere Wahrheitstafel haben? Die Antwort lautet offensichtlich ja; wir können folgende Wahrheitstafeln bilden:
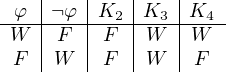
Das erste Konnektiv ist unsere Negation; es kehrt den Wahrheitswert des Satzes um, auf den es angewandt wird. Das zweite Konnektiv gibt es in unserer Sprache nicht; es liefert in jedem Fall den Wert F. Das dritte Konnektiv liefert stets W; auch ein solches Konnektiv fehlt in unserer logischen Sprache. Das letzte Konnektiv, K4, lässt den Wahrheitswert des Satzes, auf den es angewandt wird, unverändert. Auch über dieses Konnektiv verfügen wir nicht.
Wie sehr fehlen uns die fehlenden Konnektive? Nun, man mag argumentieren, dass die Konnektive K2 bis K4 nutzlos seien. Da Nutzen keine philosophische Kategorie ist, sollten wir einen anderen Zugang suchen: Kann man mit Hilfe der Konnektive K2 bis K4 irgendetwas ausdrücken, was man ohne sie nicht ausdrücken kann? Erfreulicherweise ist das nicht der Fall. Möchte man einen Satz φ so umformulieren, dass er stets falsch ist (das entspricht Konnektiv K2), dann schreibt man ganz einfach φ∧¬φ. Dieser Ausdruck ist zwar etwas lang, aber wenn die Leserin die Wahrheitstabelle für ihn aufstellt, wird sie sehen, dass er tatsächlich konstant falsch ist.
Möchte man aus φ einen konstant wahren Satz formen (K3), so schreibt man ganz einfach z.B. φ ∨¬φ. Auch das ist länger als es ein eigenes Konnektiv wäre, erspart uns aber das Auswendiglernen überflüssig vieler logischer Zeichen.
Wie man vorgehen muss, um Konnektiv K4, das den Wahrheitswert eines Satzes unverändert lässt, nachzuahmen, möge der Leser selbst herausfinden. Ein kleiner Tip: Man muss überhaupt nichts tun.
Bei den zweistelligen Konnektiven ist der Sachverhalt komplizierter. Die Leserin wird gebeten, an dieser Stelle innezuhalten und zu überlegen, wieviele zweistellige Konnektive es geben mag, pathologische Fälle mit eingeschlossen (also z.B. ein zweistelliges Konnektiv, das immer W liefert).
Die aufwendigste Methode, die gesuchte Anzahl herauszufinden, besteht darin, alle Möglichkeiten aufzuschreiben und anschließend zu zählen:
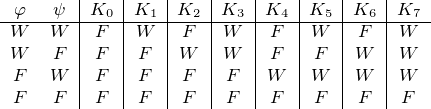

Wie man sieht, gibt es sechzehn zweistellige Konnektive. Wirklich überraschend ist das nicht: Eine Wahrheitstafel für ein zweistelliges Konnektiv hat vier Zeilen. In der ersten Zeile muss das Konnektiv entweder W oder F liefern; für die erste Zeile gibt es also zwei Möglichkeiten. Auch in der zweiten Zeile muss einer der beiden Wahrheitswerte stehen; die Zahl der Möglichkeiten in der ersten Zeile wird daher verdoppelt (2 × 2). Dadurch, dass auch in der dritten Zeile einer der zwei Werte W und F steht, wird das Zwischenergebnis erneut verdoppelt – wir stehen bei 2 × 2 × 2. Da auch in der letzten Zeile einer der zwei Fälle auftreten muss, verdoppelt sich die Zahl der Möglichkeiten ein letztes Mal, und wir landen bei 2 × 2 × 2 × 2, das ist 24 bzw. sechzehn.
Da diese Liste vollständig ist, müssen auch die drei zweistelligen Konnektive unserer logischen Sprache darin auftreten: K1 ist die Konjunktion, „∧“, K7 ist die Disjunktion, „∨“, und K13 ist das Konditional, „→“. dass es die übrigen Konnektive in unserer logischen Sprache nicht gibt, sagt nichts über ihre Sinnhaftigkeit aus. Einige der sechzehn Konnektive erfreuen sich großer Bedeutung und haben auch eigene Namen. Besonders wichtig sind Konnektiv K8, das NOR oder NichtoderNOR, und Konnektiv K14, NAND oder NichtundNAND.4 Konnektiv K6, das ausschließende Oder („entweder …oder“, lateinisch aut), hat in der Kryptologie (Verschlüsselung) eine hervorragende Stellung inne; es ist dort als Vernam-Chiffrierschritt (unvollständige Addition) bekannt.5 Die Leserin möge darüber nachdenken, welche der übrigen Konnektive in welcher Weise bedeutsam sein könnten.
Unabhängig von der Frage, ob alle sechzehn Konnektive in irgendeiner Hinsicht sinnvoll sind, lässt sich wie bei den einstelligen Konnektiven die Frage stellen, welche von ihnen nötig sind. Dazu ist folgende Definition hilfreich: Eine Menge von Konnektiven heißt funktional vollständigfunktional vollständig, wenn sich mit Hilfe dieser Konnektive jedes andere Konnektiv ausdrücken lässt. Die Menge unserer Konnektive, {¬,∧,∨,→} ist funktional vollständig. Es wäre eine gute Übung, an dieser Stelle innezuhalten und zu versuchen, einige der sechzehn möglichen Konnektive mit den Konnektiven unserer logischen Sprache auszudrücken.
Ist man des Denkens überdrüssig, kann man sich folgendes Verfahrens bedienen: Man bildet für jede Wahrheitswertzuordnung, bei der das zur Diskussion stehende Konnektiv den Wert W liefert, eine Konjunktion. Das linke Konjunkt ist der Satz φ, wenn die Zuordnung dem Satz φ den Wert W zuordnet, und der Satz ¬φ, wenn sie ihm den Wert F zuordnet. Das rechte Konjunkt lautet ψ, wenn die Zuordnung dem Satz ψ den Wert W zuordnet, und ¬ψ, wenn sie ihm F zuordnet. Zuletzt werden alle so entstandenen Konjunktionen zu einer Disjunktion verbunden.
Zur Klärung wollen wir das Konnektiv K11 betrachten. Es liefert für drei Zuordnungen den Wert W, nämlich für φ _ W ψ _ W , für φ _ W ψ F und für φ F ψ F . Für jede dieser Zuordnungen müssen wir in der geschilderten Weise eine Konjunktion bilden. Die erste Konjunktion lautet (φ∧ψ), weil die erste Zuordnung beiden Sätzen den Wert W zuordnet. Die zweite Konjunktion ist (φ ∧¬ψ), weil die zweite Zuordnung dem ersten Satz W und dem zweiten Satz F zuordnet. Die dritte und letzte Konjunktion hat die Gestalt (¬φ ∧¬ψ), weil die dritte Zuordnung beiden Sätzen den Wert F zuordnet. Wenn man die drei Konjunktionen zu einer Disjunktion verbindet, gelangt man zu ((φ∧ψ)∨(φ∧¬ψ))∨(¬φ∧¬ψ)6. Zur Kontrolle kann man für diesen Satz eine Wahrheitstafel aufstellen; sie hat denselben Verlauf wie das Konnektiv K11.
Ein Sonderfall ist das Konnektiv K0; da es in keiner Zeile den Wert W liefert, ist das Verfahren nicht anwendbar. Es ist dennoch sehr einfach, K0 mit den bekannten Konnektiven nachzuahmen, indem man z.B. φ ∧¬φ oder – weil man beide Sätze unterbringen möchte – (φ ∧¬φ) ∧ ψ schreibt.
Wie im vorangehenden Kapitel bereits kurz angerissen, nennt man eine Menge von Konnektiven genau dann funktional vollständigfunktional vollständig, wenn sich mit Hilfe dieser Konnektive alle anderen Konnektive ausdrücken lassen. Die Menge unserer Konnektive, {¬,∧,∨,→}, ist funktional vollständig. Wir wollen untersuchen, ob es auch andere funktional vollständige Konnektivmengen gibt und – wenn ja – ob darunter eine ist, die weniger Konnektive enthält als die vier bekannten.
Nun, eine erste Reduktion ist sehr einfach. Auf Seite § ist es uns gelungen, ein Verfahren anzugeben, mit dem alle Konnektive bloß mit ¬, ∧ und ∨ ausgedrückt werden können. Daher ist es unmittelbar klar, dass die Menge {¬,∧,∨} funktional vollständig ist. Das ist insoferne ein erfreuliches Ergebnis, als wir auf das mancherorts unbeliebte Konditional verzichten könnten.
Wenn es uns gelänge, eines der Konnektive der Menge {¬,∧,∨} durch die beiden anderen auszudrücken, dann könnten wir eine noch kleinere funktional vollständige Konnektivmenge bilden. An dieser Stelle wäre wieder einmal eine gute Gelegenheit, innezuhalten und ein wenig nachzudenken: Ist es möglich, das Oder nur mit Hilfe des Nicht und des Und auszudrücken?
Ein Satz der Form φ ∨ ψ sagt aus, dass mindestens eines der beiden Disjunkte zutrifft. Wenn mindestens ein Disjunkt zutrifft, dann kann es nicht der Fall sein, dass beide Disjunkte nicht zutreffen. Das kann man aufschreiben: ¬(¬φ∧¬ψ).7 Diese Aussage aber enthält kein Oder mehr – wir haben unser Ziel erreicht und gezeigt, dass schon die Menge {¬,∧} funktional vollständig ist.
Übrigens sind auch die Mengen {¬,→} sowie {¬,∨} funktional vollständig – der Nachweis bleibt der Leserin zur Übung überlassen.
Die Suche nach funktional vollständigen Mengen ist keine sinnleere Spielerei; vielen Menschen fällt es schwer, sich logische Zeichen auswendig zu merken. Für sie ist es eine große BeruhigungBeruhigung zu wissen, dass man mit nur zwei Konnektiven eine logische Sprache aufbauen kann, die um nichts weniger ausdrucksstark ist als die hier vorgestellte mit ihren vier Konnektiven.
Wäre es denkbar, die Zahl der Konnektive noch weiter zu verringern, also eine funktional vollständige Menge zu finden, die nur ein einziges Konnektiv umfasst? – So überraschend das ist, die Antwort lautet ja.
Erinnern wir uns an Konnektiv K14, für seine Freunde NANDNAND. Mit seiner Hilfe lässt sich jedes andere Konnektiv ausdrücken. Die Verneinung ¬φ wird formuliert als φ NAND φ, und die Konjunktion φ ∧ ψ als (φ NAND ψ) NAND (φ NAND ψ) – der Zweifler möge sich einmal mehr mit einer Wahrheitstabelle von der Wahrheit meiner Behauptung überzeugen. Da wir mittels des NAND sowohl das Nicht als auch das Und ausdrücken können, können wir mit seiner Hilfe in der Tat jedes Konnektiv ausdrücken, weil wir ja bereits gezeigt haben, dass die Menge {¬,∧} funktional vollständig ist. Somit ist auch die Menge {NAND} funktional vollständig.
Ein Konnektiv, dessen Einermenge funktional vollständig ist, das alleine also ausreicht, alle anderen Konnektive auszudrücken, wird Sheffer-FunktionSheffer-Funktion genannt. Eine andere Shefferfunktion ist das Nichtoder, NOR.
Von Leibniz stammt folgender kurzer Merksatz: Aus Wahrem folgt nur Wahres.
Semantische Gültigkeit wird durch das Zeichen „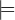 “ ausgedrückt, das wie das
Zeichen für syntaktische Gültigkeit, „⊢“, zwischen die Prämissen und die Konklusion
geschrieben wird. Um auszudrücken, dass ein Argument nicht semantisch gültig ist,
streicht man das Zeichen durch: ⁄
“ ausgedrückt, das wie das
Zeichen für syntaktische Gültigkeit, „⊢“, zwischen die Prämissen und die Konklusion
geschrieben wird. Um auszudrücken, dass ein Argument nicht semantisch gültig ist,
streicht man das Zeichen durch: ⁄ .
.
Der Schluss „Alle Katzen sind Hunde; Sokrates ist eine Katze; also ist Sokrates ein Hund“ ist semantisch gültig; denn wären beide Prämissen wahr, d.h. wären alle Katzen Hunde und wäre Sokrates eine Katze, dann wäre auch die Konklusion wahr: Sokrates wäre ein Hund.
Der Schluss „Sokrates ist der Autor von Menon; also ist Platon ein Philosoph“ ist semantisch nicht gültig: Es ist ohne weiteres denkbar, dass die Prämisse wahr ist, d.h. dass Sokrates den Menon schrieb, dass die Konklusion aber falsch ist, dass Platon also kein Philosoph ist.
Um die semantische Gültigkeit semantische Gültigkeit eines aussagenlogischen Arguments eines in der Sprache der Aussagenlogik8 formulierten Arguments zu untersuchen, muss man sich alle Zuordnungen von Wahrheitswerten zu den im Argument vorkommenden Satzbuchstaben vornehmen und für jede dieser Zuordnungen die Wahrheitswerte aller Prämissen und der Konklusion betrachten: Gibt es auch nur eine einzige Zuordnung, die alle Prämissen wahr macht, die Konklusion aber falsch, dann ist das Argument ungültig; andernfalls ist es gültig.
Man nennt jede Zuordnung, bei der alle Prämissen wahr sind, bei der die Konklusion aber falsch ist, ein GegenbeispielGegenbeispiel für das Argument. Für ein gültiges Argument gibt es kein Gegenbeispiel, denn so ist ja die semantische Gültigkeit definiert.
Um nicht den Überblick zu verlieren, wird man eine Liste aller möglichen Zuordnungen bilden. Betrachten wir das Argument P → Q,Q → R,P ⊢ R. In diesem Argument treten drei Satzbuchstaben auf, P, Q und R. Jedem von ihnen kann entweder der Wahrheitswert W oder F zugeordnet werden. Insgesamt gibt es daher 2 × 2 × 2 = 8 Zuordnungen. Sie sehen wie folgt aus:

Unsere Aufgabe besteht darin, zu untersuchen, ob auch nur eine einzige dieser acht Zuordnungen ein Gegenbeispiel für unser Argument ist und damit das Argument als semantisch ungültig erweist.
Es ist zweckmäßig, sowohl jeder Prämisse als auch der Konklusion eine eigene Spalte in unserer nun wachsenden Tabelle zu gewähren:
| erste Prämisse | zweite Prämisse | dritte Prämisse | Konklusion | |||
| P | Q | R | P → Q | Q → R | P | R |
| W | W | W | ? | ? | ? | ? |
| W | W | F | ? | ? | ? | ? |
| W | F | W | ? | ? | ? | ? |
| W | F | F | ? | ? | ? | ? |
| F | W | W | ? | ? | ? | ? |
| F | W | F | ? | ? | ? | ? |
| F | F | W | ? | ? | ? | ? |
| F | F | F | ? | ? | ? | ? |
Die erste neu hinzugekommene Spalte soll mit den Wahrheitswerten der ersten Prämisse, P → Q, für die einzelnen Wahrheitswertzuordnungen gefüllt werden. Wir kommen zu folgendem Ergebnis:
| erste Prämisse | zweite Prämisse | dritte Prämisse | Konklusion | |||
| P | Q | R | P → Q | Q → R | P | R |
| W | W | W | W → W | ? | ? | ? |
| W | W | F | W → W | ? | ? | ? |
| W | F | W | W → F | ? | ? | ? |
| W | F | F | W → F | ? | ? | ? |
| F | W | W | F → W | ? | ? | ? |
| F | W | F | F → W | ? | ? | ? |
| F | F | W | F → F | ? | ? | ? |
| F | F | F | F → F | ? | ? | ? |
Ist einem der Wahrheitswertverlauf des Konditionals bekannt, schreibt man ohne große Mühe das „Endergebnis“ der ersten Prämissenspalte nieder. Es sieht wie folgt aus:
| erste Prämisse | zweite Prämisse | dritte Prämisse | Konklusion | |||
| P | Q | R | P → Q | Q → R | P | R |
| W | W | W | W | ? | ? | ? |
| W | W | F | W | ? | ? | ? |
| W | F | W | F | ? | ? | ? |
| W | F | F | F | ? | ? | ? |
| F | W | W | W | ? | ? | ? |
| F | W | F | W | ? | ? | ? |
| F | F | W | W | ? | ? | ? |
| F | F | F | W | ? | ? | ? |
In derselben Weise verfährt man für die beiden verbleibenden Prämissenspalten und für die Konklusionsspalte. Die Tabelle nimmt folgende Gestalt an:
| erste | zweite | dritte | Konklu- | ||||
| Prämisse | Prämisse | Prämisse | sion | ||||
| P | Q | R | P → Q | Q → R | P | R | |
| W | W | W | W | W | W | W | erste Zuordnung |
| W | W | F | W | F | W | F | zweite Zuordnung |
| W | F | W | F | W | W | W | dritte Zuordnung |
| W | F | F | F | W | W | F | vierte Zuordnung |
| F | W | W | W | W | F | W | fünfte Zuordnung |
| F | W | F | W | F | F | F | sechste Zuordnung |
| F | F | W | W | W | F | W | siebente Zuordnung |
| F | F | F | W | W | F | F | achte Zuordnung |
Die erste Zuordnung, das ist jene, die allen drei Satzbuchstaben den Wert W zuordnet, ordnet allen drei Prämissen ebenfalls den Wert W zu. Auch der Konklusion ordnet sie W zu.
Da es keine weitere Zuordnung gibt, die alle Prämissen wahr werden lässt, wissen
wir bereits, dass das untersuchte Argument gültig ist: Es ist tatsächlich der Fall, dass
alle Zuordnungen, die alle Prämissen wahr machen (im Beispiel gibt es nur eine
solche Zuordnung, eben die erste) auch die Konklusion wahr machen. Wir schreiben
daher P → Q,Q → R,P R.
R.
Eigennamen sind sprachliche Zeichen, die die Aufgabe haben, genau ein Individuum zu bezeichnen. Eigennamen, die diese Aufgabe nicht erfüllen, sollen im Folgenden nach Gottlob Frege als ScheinnamenScheinname bezeichnet werden. Ein Scheinname ist z.B. „Pegasus“, denn Pegasus, das geflügelte Pferd, existiert nicht; daher ist es nicht der Fall, dass das Zeichen „Pegasus“ genau ein Individuum bezeichnet.
Die Beziehung, die zwischen einem Namen und dem Gegenstand besteht, den dieser Name bezeichnet, heißt wenig überraschend NamensbeziehungNamensrelation oder Namensrelation. Eine Namensbeziehung besteht z.B. zwischen dem Namen „Sokrates“ und einem bekannten griechischen Philosophen.
Die Annahme, dass an einer Namensrelationzweistellige Namensrelation nur zwei Komponenten beteiligt sind, nämlich der Name und das Benannte, ist jedoch eine – wahrscheinlich unzulässige – Vereinfachung, die zu vielen Problemen führt. Dieses Thema wird in Kapitel 5.3 (Seite §) näher behandelt.
Es lassen sich verschiedene Arten von Eigennamen unterscheiden.
Als eigentliche Eigennamen bezeichnet man solche Namen, die auch in der Umgangssprache als Eigennamen bezeichnet werden, also Ausdrücke wie „Sokrates“, „Immanuel Kant“, „Groucho Marx“ oder „Pegasus“. Der letzte dieser vier ist ein Scheinname.
Kennzeichnungen oder bestimmte Beschreibungen haben die Aufgabe, genau ein Ding zu beschreiben und damit zu benennen. Beispiele sind „der gegenwärtige König von Frankreich“ (ein Scheinname), „der (gegenwärtige) österreichische Bundeskanzler“, „die größte Primzahl“ (ein Scheinname) oder „die kleinste Primzahl“.
Auch sie haben die Aufgabe, genau ein Ding zu bezeichnen. Beispiele sind „ich“, „er“ oder „dieser da“.
Kollektive Eigennamen sind Namen, die nur im Singular auftreten, für Dinge, die nicht gezählt werden.
Beispiele: „Wasser“, „Butter“, „Blut“
Warum bezeichnen Wörter wie „Wasser“ genau ein Ding? Nun, man kann alles Wasser, das es gibt, gegeben hat und geben wird, als einen diskontinuierlichen, vierdimensionalen, in der Raum-Zeit verstreuten Gegenstand auffassen, der den Namen „Wasser“ trägt.
Ein Prädikat im logischen Sinn ist eine Aneinanderreihung von Wörtern einer natürlichen Sprache, die mindestens null Leerstellen enthält und die zu einem Aussagesatz der natürlichen Sprache wird, wenn in jede Leerstelle ein Eigenname eingesetzt wird. Die Zahl der Leerstellen, die ein Prädikat enthält, ist die StelligkeitStelligkeit des Prädikats.
Leerstellen werden im Folgenden durch das Auslassungszeichen „ “ gekennzeichnet. Enthält ein Satz mehrere Leerstellen, werden sie numeriert, lauten also „ 1 “, „ 2 “ usw.
Nach oben stehender Definition sind folgende Gebilde Prädikate:
Dieser Satz enthält keine Leerstelle und ist daher ein nullstelliges Prädikat.
Diese Folge von Wörtern enthält eine Leerstelle und ist somit ein einstelliges Prädikat. Wird in eine Leerstelle ein Eigenname eingesetzt (z.B. „die gegenwärtige Königin von England“), so entsteht ein Satz der natürlichen Sprache (im Beispiel „Die gegenwärtige Königin von England ist ein Nilpferd“).
Diese Folge von Wörtern enthält zwei Leerstellen und ist damit ein zweistelliges Prädikat. Wird in eine der Leerstellen ein Eigenname eingesetzt, entsteht ein einstelliges Prädikat, z.B. „Platon ist kleiner als “ oder „ ist kleiner als Sokrates“. Wird in beide Leerstellen je ein Eigenname eingesetzt, entsteht ein Satz der deutschen Sprache, z.B. „Sokrates ist kleiner als Platon“ oder „Sokrates ist kleiner als Sokrates“.
Wie man unmittelbar sieht, ist diese Folge von Wörtern ein dreistelliges Prädikat.
Haben mehrere Leerstellen dieselbe Nummer, bedeutet das, dass in sie derselbe Name eingesetzt werden muss. So drückt z.B. das Prädikat „ 1 liebt 1 “ die Eigenschaft der Eigenliebe aus.
Betrachtet man die Sätze „Alles ist eitel“ und „Jemand ist eitel“ sowie das Prädikat „ ist eitel“, so scheint es, als wären die Wörter „alles“ und „jemand“ Eigennamen, geeignet, die Leerstellen von Prädikaten auszufüllen.
Eine einfache Überlegung lehrt, dass dem nicht so ist. Betrachten wir folgenden scheinbaren Schluss:
| Jemand ist der Autor von Sein und Zeit. |
| Ich sah das Bild von jemandem. |
| Also sah ich das Bild des Autors von Sein und Zeit. |
Die erste Prämisse stimmt. Das Buch Sein und Zeit hat tatsächlich einen Autor. Auch die zweite Prämisse trifft zu: Ich habe jemandes Bild gesehen, nämlich das Bild Kaiser Franz Josephs. Und doch ist der Schluss nicht korrekt – ich habe das Bild des Autors von Sein und Zeit nämlich nicht gesehen.
Steht im obigen Schluss an der Stelle des Wortes „jemand“ ein Eigenname, dann ist der Schluss korrekt:
| Groucho Marx ist der Autor von Sein und Zeit. |
| Ich sah das Bild von Groucho Marx. |
| Also sah ich das Bild des Autors von Sein und Zeit. |
Das zeigt, dass das Wort „jemand“ von anderer Art als ein Eigenname sein muss.
Diese Erkenntnis ist nicht allzu überraschend. In der Tat meinen wir auch im täglichen Leben, wenn wir einen Satz der Form „Jemand hat mir meine Geldtasche gestohlen“ äußern, nicht, dass genau eine Person, die den Namen „Jemand“ trägt, ein Eigentumsdelikt beging; was wir sagen möchten ist vielmehr, dass es mindestens eine Person gibt, die diesen Frevel auf sich lud.
Ähnlich verhält es sich mit den Wörtern „jeder“, „alles“, „alle“ oder „nichts“. Der Satz „Jeder ist sterblich“ bedeutet nicht, dass Frau Jeder vergänglich ist, sondern vielmehr, dass das Prädikat „ist sterblich“ wahr wird, welchen Eigennamen auch immer wir in die Leerstelle einsetzen.
Der Satz „Nichts ist unsterblich“ bedeutet nicht, dass ein geheimnisvolles Individuum namens „Nichts“ ewig lebt, sondern vielmehr, dass das Prädikat „ ist unsterblich“ zu einem falschen Satz wird, über welches Individuum auch immer wir es aussagen mögen, oder anders formuliert: dass wir kein Ding finden können, das unsterblich ist.
Ausdrücke, die sich nicht auf ein bestimmtes Individuum beziehen, sondern die eine Aussage darüber erlauben, auf wieviele Individuen ein Prädikat zutrifft, heißen QuantifikatorenQuantifikatoren, Quantorem oder Quantoren. Mithin sind Wörter wie „alle“, „jeder“, „nichts“, „niemand“, „keiner“, „viele“ oder „wenige“ Quantoren.
Die Sprache der Prädikatenlogik wird dazu verwendet, über bestimmte Individuen zu sprechen. Die Menge der Individuen, über die gesprochen wird, heißt DiskursuniversumDiskursuniversum (englisch universe of discourse oder domain). Quantifizierte Aussagen sind relativ zum Diskursuniversum zu verstehen: Der Satz „Alles ist eitel“ bedeutet, dass jedes der zur Diskussion stehenden Dinge eitel ist.
Das Diskursuniversum kann endlich viele Individuen (z.B. lebende Philosophen), aber auch unendlich viele Individuen (z.B. Zahlen) enthalten. Das Diskursuniversum darf aber nicht leer sein.10
Wenn das Diskursuniversum sinnvoll wenige endlich viele Individuen enthält, lässt es sich graphisch veranschaulichen, indem man die Individuen aufschreibt und eine geschlossene Linie um sie herum zieht.
Das Diskursuniversum von Abbildung 4.1 (Seite §) umfasst zwölf Dinge, nämlich die Meerjungfrau Arielle, die österreichischen Politiker Schüssel, Vranitzky und Haider, Dumbo, Walt Disneys fliegenden Elephanten, die Zahl fünf, den Kater Garfield, den griechischen Gott Apoll, den Unternehmer Dagobert Duck und die drei Philosophen Sokrates, Platon und Aristoteles.
Jede der Individuenkonstanten a, b, c, …, a1, a2, a3, …bezeichnet genau ein Individuum. Ein Individuum kann auch von mehr als einer Individuenkonstante bezeichnet werden. Ebenso ist es möglich, dass es „namenlose“ Individuen gibt, die von keiner Individuenkonstante bezeichnet werden; das ist zum Beispiel dann der Fall, wenn das Diskursuniversum die Menge der reellen Zahlen ist: Obwohl es unendlich viele Individuenkonstanten gibt, gibt es „noch mehr“ reelle Zahlen, sodass es gar nicht möglich wäre, für jedes Individuum eine Individuenkonstante zu finden.
Eine Möglichkeit, den Individuen des Diskursuniversums von Abbildung 4.1 (Seite §) Individuenkonstanten zuzuordnen, findet sich in Abbildung 4.2 (Seite §).
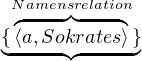
Die Beziehung, die zwischen einer Individuenkonstante und dem von ihr bezeichneten Individuum besteht, ist eine zweistellige NamensrelationNamensrelation (vgl. Kapitel 4.3, Seite §).
Die Namensrelationen des vorangegangenen Beispiels sind in Abbildung 4.3 (Seite §) dargestellt.
EinExtension eines einstelligen Prädikats einstelliges Prädikat trifft auf bestimmte Individuen zu. Die Menge der Individuen, auf die das Prädikat zutrifft, heißt Extension des Prädikats.
Beispiel: Wenn das Diskursuniversum die Zahlen 1 bis 10 enthält, dann ist die Extension des Prädikats „ ist ungerade“ die Menge {1,3,5,7,9}.
Ein zweistelliges Prädikat wird wahr, wenn in seine beiden Leerstellen die Namen von bestimmten Individuen eingesetzt werden. So wird zum Beispiel das Prädikat „ ist größer als “ wahr, wenn in die erste Leerstelle der Name „Wien“, in die zweite Leerstelle der Name „Stixneusiedl“ eingesetzt wird. Zwei Individuen, durch Einsetzung deren Namen ein zweistelliges Prädikat erfüllt wird, kann man zu einem geordneten Paar zusammenfassen, im Beispiel zum Paar ⟨Wien, Stixneusiedl⟩.11 DieExtension eines zweistelligen Prädikats Extension des zweistelligen Prädikats ist die Menge aller geordneten Paare ⟨γ,δ⟩ von Individuen γ und δ aus dem Diskursuniversum, auf die das Prädikat zutrifft.
Beispiel: Wenn das Diskursuniversum die Zahlen 1, 2, 3 und 4 enthält, dann ist die Extension des Prädikats „ 1 ist kleiner als 2 “ folgende Menge: {⟨1,2⟩,⟨1,3⟩,⟨1,4⟩,⟨2,3⟩,⟨2,4⟩,⟨3,4⟩}.
Allgemein ist die Extension eines n-stelligen PrädikatsExtension eines n-stelligen Prädikats die Menge aller geordneten n-Tupel ⟨γ,γ1,…,γn⟩, sodass das Prädikat wahr wird, wenn Namen für die Individuen γ1 bis γn in dieser Reihenfolge seine Leerstellen ausfüllen.
Beispiel: Wenn das Diskursuniversum die Zahlen 1, 2, 3, 4 und 5 enthält, ist die Extension des Prädikats „ 1 liegt unmittelbar zwischen 2 und 3 “ die Menge {⟨2,1,3⟩,⟨2,3,1⟩,⟨3,2,4⟩,⟨3,4,2⟩,⟨4,3,5⟩,⟨4,5,3⟩}.
Die folgende Definition ist nicht völlig zufriedenstellend. Sie drückt aber gut aus, worum es geht, und reicht daher für den Anfang.12
In etwas weniger formaler Form: Der Satz ∧ αφ(α) ist ganz einfach genau dann wahr, wenn der Satz φ auf jedes Individuum zutrifft. Andernfalls ist er falsch.
In Kapitel 4.2 (Seite §) haben wir uns damit befasst, aussagenlogische Argumente auf ihre semantische Gültigkeit hin zu untersuchen. In diesem Kapitel wollen wir unsere Untersuchung auf die volle Prädikatenlogik ausdehnen.
Hier zur Erinnerung noch einmal die Definition semantischer Gültigkeit:
Um die Wahrheit eines Satzes der Aussagenlogik zu kennen, reicht es aus, die Wahrheit der in ihm vorkommenden Satzbuchstaben zu kennen. Mit dieser Information lässt sich der Wahrheitswert des ganzen Satzes errechnen. Um alle Möglichkeiten zu prüfen, in denen die Prämissen theoretisch alle wahr sein können und die Konklusion falsch sein kann, reicht es aus, alle Zuordnungen von Wahrheitswerten zu allen im Satz auftretenden Satzbuchstaben zu untersuchen.
Die Prädikatenlogik besteht aus weitaus mehr Komponenten. Um den Wahrheitswert eines prädikatenlogischen Satzes feststellen zu können, benötigt man folgende Informationen:
Diese Information liefert das Diskursuniversum (vgl. Kapitel 4.6.1, Seite §).
Diese Information liegt in Gestalt von Namensrelationen vor (vgl. Kapitel 4.6.2, Seite §).
Diese Information liefert eine Wahrheitswertzuordnung, wie wir sie aus der reinen Aussagenlogik kennen (vgl. Kapitel 4.1.1, Seite §).
Diese Information liefern die Extensionen der Prädikate (vgl. Kapitel 4.6.3, Seite §).
All diese Informationen liefert einem eine Interpretation: Ein geordnetes
Quadrupel ⟨ ,
, ,
,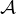 ,
,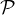 ⟩ heißt genau dann InterpretationInterpretation eines
prädikatenlogischen Satzes
⟩ heißt genau dann InterpretationInterpretation eines
prädikatenlogischen Satzes 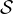 , wenn folgende Bedingungen zutreffen:
, wenn folgende Bedingungen zutreffen:
ist ein Diskursuniversum, d.h. eine Menge von beliebigen Individuen
ist eine Menge von Namensrelationen, d.h. von geordneten Paaren
⟨ι,δ⟩, bei denen ι eine Individuenkonstante und δ ein Individuum,
also ein Element des Diskursuniversums ist; dabei darf für jede
Individuenkonstante höchstens eine Namensrelation enthalten (andernfalls
wäre die Individuenkonstante mehrdeutig, also ein Scheinname). Für jede
Individuenkonstante, die im interpretierten Satz vorkommt, muss
eine Namensrelation enthalten, weil der Satz sonst einen Scheinnamen
enthielte, der nichts bezeichnet.
ist eine Menge von Satzbuchstaben, denen der Wahrheitswert W
zugeordnet wird. Satzbuchstaben, die nicht in enthalten sind, wird der
Wert F zugeordnet.
ist eine Menge von geordneten Paaren ⟨φ,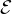 ⟩, bei denen φ ein
Prädikatbuchstabe und die Extension dieses Prädikatbuchstaben
ist; dabei darf für jeden Prädikatbuchstaben höchstens ein solches
Paar enthalten (andernfalls wäre das Prädikat mehrdeutig). Für jeden
Prädikatbuchstaben, der im interpretierten Satz vorkommt, muss ein
solches Paar enthalten, weil der Satz sonst ein unverständliches Prädikat
enthielte.
⟩, bei denen φ ein
Prädikatbuchstabe und die Extension dieses Prädikatbuchstaben
ist; dabei darf für jeden Prädikatbuchstaben höchstens ein solches
Paar enthalten (andernfalls wäre das Prädikat mehrdeutig). Für jeden
Prädikatbuchstaben, der im interpretierten Satz vorkommt, muss ein
solches Paar enthalten, weil der Satz sonst ein unverständliches Prädikat
enthielte.  ,
, ,
, ,
, ⟩ für den Satz ∧
xFx∧Fa bilden. Das
Diskursuniversum können wir frei wählen; entscheiden wir uns für {Frege,
Russell, Carnap, Quine, Sokrates, Garfield}. Die Menge muss für alle
im Satz vorkommenden Individuenkonstanten eine Namensrelation enthalten.
Unser Beispielsatz enthält bloß die Individuenkonstante a. Wenn wir uns dafür
entscheiden, a das Individuum Sokrates bezeichnen zu lassen, dann lautet die
Namensrelation ⟨a,Sokrates⟩. Da der Satz keine weiteren Individuenkonstanten
enthält, ist die Menge {⟨a,Sokrates⟩} als Komponente ausreichend.
Zwar wäre es zulässig, noch weitere Namensrelationen aufzunehmen – z.B.
⟨b,Quine⟩ – doch brächte das keinen Vorteil.
⟩ für den Satz ∧
xFx∧Fa bilden. Das
Diskursuniversum können wir frei wählen; entscheiden wir uns für {Frege,
Russell, Carnap, Quine, Sokrates, Garfield}. Die Menge muss für alle
im Satz vorkommenden Individuenkonstanten eine Namensrelation enthalten.
Unser Beispielsatz enthält bloß die Individuenkonstante a. Wenn wir uns dafür
entscheiden, a das Individuum Sokrates bezeichnen zu lassen, dann lautet die
Namensrelation ⟨a,Sokrates⟩. Da der Satz keine weiteren Individuenkonstanten
enthält, ist die Menge {⟨a,Sokrates⟩} als Komponente ausreichend.
Zwar wäre es zulässig, noch weitere Namensrelationen aufzunehmen – z.B.
⟨b,Quine⟩ – doch brächte das keinen Vorteil.
Satzbuchstaben kommen im zu interpretierenden Satz keine vor. Wir verwenden
für der Einfachheit halber die leere Menge, {}. Das bedeutet, dass keinem
einzigen Satzbuchstaben der Wert W zugeordnet wird.
unserer
Interpretation auf.
zu bilden, fertig: Sie lautet:
⟨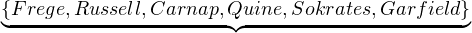 Diskursuniversum
Diskursuniversum  ,
,
 ,
, Menge der wahren Satzbuchstaben
Menge der wahren Satzbuchstaben 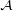 ,
,
 ⟩
⟩
Eine Interpretation eines prädikatenlogischen Satzes erlaubt es, seinen Wahrheitswert gemäß den Wahrheitsregeln von Kapitel 4.6.4 (Seite §) zu berechnen.
Eine InterpretationModell für einen Satz , die diesen Satz wahr macht, heißt
Modell von . Hat ein Satz kein Modell, ist er unerfüllbar.unerfüllbar Hat ein Satz
mindestens ein Modell, ist er erfüllbarerfüllbar. Ist ein Satz bei jeder Interpretation
wahr, dann ist er allgemeingültigallgemeingültig.
Um die semantische Gültigkeit ausdrücken zu können, müssen wir die
Definition von „Interpretation“ auf mehrere Sätze, d.h. auf eine Satzmenge
ausdehnen: Ein Quadrupel ⟨,,,⟩ ist genau dann eine Interpretation für eine
Satzmenge, wenn es eine Interpretation für jeden Satz dieser Satzmenge ist. Diese
Festlegung stellt sicher, dass jeder Satz auch dann vollständig interpretiert
wird, wenn nicht alle Sätze dieselben Individuenkonstanten und Prädikate
enthalten.
Die semantische Gültigkeit eines prädikatenlogischen Arguments lässt sich damit folgendermaßen ausdrücken:
Eine InterpretationGegenbeispiel, die ein Argument widerlegt, indem sie alle Prämissen wahr, die Konklusion aber falsch macht, heißt wie in der Aussagenlogik Gegenbeispiel.
Obwohl komplizierter zu verstehen, unterscheidet sich die Semantik der Prädikatenlogik in den bisherigen Punkten nicht unerträglich von jener der Aussagenlogik. Erst wenn man mit dem bisher Gesagten an ein konkretes Argument herantritt, sieht man den großen Unterschied:
Schon allein dadurch, dass man für die Wahl der Anzahl von Individuen unendlich viele Möglichkeiten hat (das Diskursuniversum kann ein Individuum, zwei Individuen, drei, vier, …, unendlich viele Individuen, …enthalten), kann man für jeden prädikatenlogischen Satz unendlich viele Interpretationen finden. Da man nicht unendlich viele Interpretationen aufschreiben kann, gibt es in der Prädikatenlogik nichts, das dem Wahrheitstafeltest der Aussagenlogik vergleichbar wäre.
In der Tat gibt es kein Verfahren, das entscheidet, ob ein prädikatenlogisches Argument gültig ist oder ungültig.
Da man zum Nachweis der Gültigkeit unendlich viele Interpretationen untersuchen müsste, beschäftigt man sich zunächst statt dessen mit dem Nachweis von Ungültigkeit: Sobald man eine einzige Interpretation gefunden hat, die die Prämissen wahr, die Konklusion aber falsch macht, steht fest, dass das Argument semantisch ungültig ist. Solange man keine solche Interpretation gefunden hat, ist keine Aussage möglich: Das Argument könnte gültig sein; genauso gut wäre es aber möglich, dass das Argument zwar ungültig ist, man aber die Interpretation, die das zeigt, noch nicht gefunden hat.
Lange bemühte sich die Philosophie um die Klärung der Frage, was es denn mit dem Begriff „Begriff“ auf sich habe. Die Antwort auf diese Frage lieferte der deutsche Philosoph und Mathematiker Gottlob Frege am Ende des vorigen Jahrhunderts13.
Betrachten wir zur Erklärung Abbildung 4.4 (Seite §). Sie zeigt ein übersichtliches Diskursuniversum.
Widmen wir uns weiters dem Begriff „Mensch“. Einige der oben stehenden Dinge fallen unter diesen Begriff, andere nicht. Wir können die Dinge, die unter den Begriff „Mensch“ fallen, optisch hervorheben, indem wir eine geschlossene Linie um sie herum ziehen, wie das in Abbildung 4.5 (Seite §) geschehen ist.
Alle Dinge innerhalb der neuen Linie fallen unter den Begriff „Mensch“, alle Dinge außerhalb der Linie nicht. Die Linie ist damit eine Abgrenzung der Dinge, die Menschen sind, von den Dingen, die keine Menschen sind. Das lateinische Wort für Abgrenzung oder Grenze lautet terminus – daher rührt das Fremdwort „Terminus“Terminus als Synonym für das Wort „Begriff“.
Die Dinge innerhalb der Grenzlinie nennt man den UmfangBegriffsumfang des Begriffes „Mensch“. Ein Begriffsumfang ist nichts anderes als die Extension eines einstelligen Prädikats gemäß Kapitel 4.6.3 (Seite §). Es besteht daher einiger Grund, der Idee Freges zu folgen.
Beispiel: Der Begriff „Mensch“ ist das einstellige Prädikat „ ist ein Mensch“.
Beispiel: Der Begriff „Schwein“ ist das einstellige Prädikat „ ist ein Schwein“.
Umgekehrt bildet auch jedes einstellige Prädikat einen Begriff.
Beispiel: Das einstellige Prädikat „ ist größer als Sokrates“ ist der Begriff „Größersein als Sokrates“.
Beispiel: Das einstellige Prädikat „ 1 liebt 1 “ ist der Begriff „Eigenliebe“.
Prädikate dürfen uneingeschränkt mittels Prädikatbuchstaben übersetzt werden. Begriffe, also einstellige Prädikate, werden mit einstelligen Prädikatbuchstaben übersetzt.
Beispiele:
| ist ein Mensch. | M |
| Sokrates ist ein Philosoph. | P |
| 1 ist größer als 2 | F 1 2 |
In der Sprache der Prädikatenlogik gibt es genau zwei Quantoren, nämlich ∧ , den Allquantor, und ∨ , den Existenzquantor. Der Allquantor sagt aus, dass ein Prädikat wahr wird, auf welches Individuum auch immer er angewandt wird. Der Existenzquantor sagt aus, dass es mindestens ein Individuum gibt, auf das das Prädikat zutrifft.
Um einen quantifizierten Satz der natürlichen Sprache in die logische Sprache zu übersetzen, geht man am besten schrittweise vor:
| (1) | Alles ist eitel. |
| (2) | Jedes Ding ist eitel. |
| (3) | Für jedes Ding gilt, dass es eitel ist. |
| (4) | Für jedes Ding x gilt, dass x eitel ist. |
| (5) | Für jedes Ding x gilt: x ist eitel. |
| (6) | ∧ x: x ist eitel. |
| (7) | ∧ xFx, wobei „F “ bedeuten soll: „ ist eitel“. |
Etwas schwieriger zu übersetzen sind Sätze wie „Es gibt genau einen Philosophen“, oder „Es gibt höchstens einen Philosophen“. Der Leser wird gebeten, sich vor dem Weiterlesen selbst an diesen Sätzen zu versuchen.
Der einfachere der beiden Sätze ist „Es gibt höchstens einen Philosophen“. Eine Paraphrase könnte lauten „Für jedes Ding gilt: Wenn es ein Philosoph ist, dann muss jeder andere Philosoph mit diesem Ding identisch sein (wäre dem nicht so, dann gäbe es ja mehr als einen Philosophen)“ – in der logischen Sprache: ∧ x(Px →∧ y(Py → x = y)). Eine andere Möglichkeit, denselben Sachverhalt wiederzugeben, ist ∧ x∧ y((Px ∧ Py) → x = y) – soviel wie „Für alle zwei Dinge gilt: Wenn beide Philosophen sind, müssen sie identisch sein (andernfalls gäbe es ja mehr als einen Philosophen)“.
Der Satz „Es gibt genau einen Philosophen“ ist kaum komplizierter; er besagt, dass es mindestens einen (∨ xPx) und höchstens einen (∧ x∧ y((Px ∧ Py) → x = y))) Philosophen gibt: ∨ xPx ∧∧ x∧ y((Px ∧ Py) → x = y). Dabei steht der einstellige Prädikatbuchstabe P für das Prädikat „ ist ein Philosoph“.
Unpräzise Quantoren („viele“, „wenige“, „die meisten“, …) gibt es in unserer logischen Sprache nicht. Ein Satz vom Typ „Die meisten Philosophen sind weise“ lässt sich daher nicht zerlegen, sondern nur als Ganzes mit Hilfe eines Satzbuchstaben übersetzen.14
„Echte“ Eigennamen, d.h. solche Eigennamen, die tatsächlich genau ein Ding bezeichnen und in der Terminologie Freges daher keine Scheinnamen sind, werden als Individuenkonstanten in die Sprache der Prädikatenlogik übersetzt.
Beispiel: „Sokrates“ …a „Harpo Marx“ …b „Gottlob Frege“ …g „der Autor des Menon“ …c „die gegenwärtige Königin von England“ …e
Wichtig: Scheinnamen können und dürfen nicht mit Individuenkonstanten übersetzt werden. Individuenkonstanten bezeichnen Individuen, d.h. Dinge, d.h. Existierendes.
Eine alternative Art, Eigennamen zu übersetzen, schlägt Quine Quine über Eigennamen vor.15 Er führt Prädikate der Form „ ist Sokrates“ oder, auf Englisch, „ is socratizing“ vor.
Der Vorteil der Quineschen Methode liegt darin, dass positive (Sokrates existiert) und negative Existenzbehauptungen (Sokrates existiert nicht) innerhalb der logischen Sprache Sinn bekommen; arbeitet man mit Individuenkonstanten, sind positive Existenzbehauptungen trivial wahr (∨ xx = a), negative Existenzbehauptungen trivial falsch (¬∨ xx = a).
Die Nachteile der Methode Quines bestehen einerseits in einem Verlust an Intuitivität, geht doch der Unterschied zwischen Namen und Prädikaten verloren; andererseits darin, dass die prädikatenlogischen Ausdrücke komplexer und unübersichtlicher werden.
Beispiel: „Sokrates existiert.“
„Sokrates“ …a
∨ xx = a
„Es gibt mindestens ein Ding, das mit Sokrates identisch ist“ – dieser Satz ist trivial wahr.
„ ist ein Sokrates“ …S
∨ xSx
„Es gibt mindestens ein Ding, das ein Sokrates ist“ bzw. „Es gibt mindestens einen Sokrates.“
oder sogar
∨ x(Sx ∧∧ y(Sy → x = y))
„Es gibt mindestens einen Sokrates, und jeder Sokrates ist mit diesem einen Sokrates identisch“, mit anderen Worten: „Es gibt genau einen Sokrates.“
Diese Sätze sind nicht trivial wahr, sondern liefern jemandem, der sie noch nicht gekannt hat, Erkenntnis.
Beispiel: „Sokrates ist ein Philosoph.“
„Sokrates“ …a
„ ist ein Philosoph“ …F
Fa …„Sokrates ist ein Philosoph.“
„ ist Sokrates“ …S
„ ist ein Philosoph“ …P
∨ x(Sx ∧∧ y(Sy → x = y)) ∧∧ x(Sx → Px)
„Es gibt genau einen Sokrates, und jeder Sokrates ist ein Philosoph.“
Das Gebiet der Semantik wird rascher unwegsam, als es auf den vergangenen Seiten zu erkennen war. Das vorliegende Kapitel will die inzwischen klassischen Probleme vorstellen, die Betrand Russell in seinem Bestseller On Denoting1 zur Sprache bringt. Das folgende Kapitel wird die Lösung beschreiben, die Russell im selben Text vorschlägt.
Die Leserin erinnert sich sicher noch an das Prinzip der Substitution salva veritate, das besagt, dass Namen ausgetauscht werden können, wenn sie denselben Gegenstand bezeichnen. Folgendes Argument scheint diesem Prinzip zu widersprechen:
| (1) | Scott ist der Autor von „Waverley“. |
| (2) | George IV. wollte wissen, ob Scott der Autor von Waverley ist. |
| (3) | George IV. wollte wissen, ob Scott Scott ist. |
In der ersten Zeile wird ausgesagt, dass die Namen „Scott“ und „der Autor von Waverley“ denselben Gegenstand bezeichnen. Nach dem Prinzip der Substitution salva veritate dürfen sie daher an beliebiger Stelle gegeneinander getauscht werden.
Der zweite Satz enthält die beiden Namen „Scott“ und „der Autor von Waverley. Wenn man in diesem Satz den Namen „der Autor von Waverley“ durch den Namen „Scott“ ersetzt – ein nach dem Prinzip der Substitution salva veritate zulässiger Vorgang –, dann entsteht Satz (3).
Trotz der scheinbar korrekten Anwendung des Prinzips der Substitution salva veritate liegt uns nun ein Argument vor, dessen Prämissen wahr sind, dessen Konklusion aber falsch ist – mithin ein ungültiges Argument. Eine Regel, mit der sich ein ungültiges Argument beweisen lässt, ist fehlerhaft.
Wir konnten uns in der Vergangenheit davon überzeugen, dass Aussagen wahr oder falsch sind. Wenn eine Aussage wahr ist, dann ist ihre Verneinung falsch; und wenn eine Aussage falsch ist, dann ist ihre Verneinung wahr. Eine dritte Möglichkeit gibt es nicht (Satz vom ausgeschlossenen Dritten, tertium non datur).
Wie sieht es nun mit der Aussage „Der gegenwärtige König von Frankreich hat eine Glatze“ und ihrer intuitiven Verneinung „Der gegenwärtige König von Frankreich hat keine Glatze“ aus? Einer der beiden Sätze muss wahr sein, der andere falsch. Welcher ist wahr, welcher falsch?
Geht man nun der Reihe nach alle Dinge durch, die eine Glatze haben, wird man unter ihnen den gegenwärtigen König von Frankreich nicht finden (denn Frankreich hat keinen König). Der Satz „Der gegenwärtige König von Frankreich hat eine Glatze“ wäre demnach falsch.
Geht man alle Dinge durch, die keine Glatze haben, dann wird man jedoch auch nicht auf den gegenwärtigen König von Frankreich stoßen. Der Satz „Der gegenwärtige König von Frankreich hat keine Glatze“ wäre somit nicht weniger falsch!
Wir stehen damit vor dem Problem, dass sowohl ein Satz als auch seine Verneinung falsch ist. Das ist nicht nur nicht einsichtig, sondern vor allem mit unserer logischen Sprache nicht verträglich.
Das Problem der negativen Existenzsätze ist an früherer Stelle bereits zur Sprache gekommen2. Da Russell dieses Problem gemeinsam mit den anderen lösen wollte und auch gelöst hat, wenden wir uns hier ein zweites Mal diesem Thema zu. Es geht dabei um die Frage, welchen Status negative Existenzsätze wie „Das runde Viereck existiert nicht“ oder „Pegasus existiert nicht“ haben.
lässt man den Lösungsvorschlag Quines außer acht, dann sind negative Existenzsätze entweder sinnlos oder trivial falsch. Das entspricht aber keineswegs dem natürlichen Empfinden, denn wenn ein Forscher sagt, Pegasus existiere nicht, dann spricht er weder Unsinn noch eine Trivialität.
Wenn man eine Kennzeichnung verwendet, dann behauptet man – so Russell – implizit, dass die in der Kennzeichnung ausgedrückte Eigenschaft auf genau ein Ding zutreffe. Mit anderen Worten, man benutzt nur dann eine Kennzeichnung, wenn man aussagen möchte, dass es genau ein Ding gibt, das die betroffene Eigenschaft hat.
Nach Russell sind Kennzeichnungen für sich alleine betrachtet bedeutungslos. Eine Kennzeichnung erhält erst dann einen Sinn, wenn sie im Zusammenhang eines Satzes auftritt. Der ganze Satz sagt dann aus, dass (a) genau ein Ding die in der Kennzeichnung ausgedrückte Eigenschaft hat und dass (b) das Prädikat, in dessen Leerstelle die Kennzeichnung zu stehen scheint, auf dieses Ding zutrifft.
Russell bringt als Beispiel die Kennzeichnung „der Sohn des So-und-so“. Wenn ich sage: „Der Sohn des So-und-so ist ein Philosoph“, dann habe ich damit ausgedrückt, dass (a) genau eine Person der Sohn des So-und-so ist und dass (b) diese Person ein Philosoph ist.
Da eine Kennzeichnung für sich alleine bedeutungslos ist, ist sie kein Eigenname. Kennzeichnungen können und dürfen daher nicht mit Individuenkonstanten übersetzt werden. In der Tat können Kennzeichnungen überhaupt nicht übersetzt werden (sie bedeuten ja nichts); übersetzen lassen sich nur die Sätze, in denen Kennzeichnungen vorkommen.
Die Kennzeichnungstheorie Russells löst alle angeführten Probleme, wie die folgenden Kapitel zeigen sollen.
Das Prinzip der Substitution salva veritate ist nach Russell vollkommen korrekt. Das Problem resultiert aus einer falschen Analyse: Die Kennzeichnung „der Autor von Waverley“ wurde fälschlicherweise als Eigenname behandelt. Korrekt müssten die Prämissen wie folgt übersetzt werden:
| (1) | Es gibt genau ein Ding, das Autor von „Waverley“ ist, und dieses Ding ist mit Scott identisch. |
| (2) | George IV. wollte wissen, ob folgendes der Fall ist: Es gibt genau ein Ding, das Autor von „Waverley“ ist, und dieses Ding ist mit Scott identisch. |
Aus diesen beiden Prämissen folgt die fehlerhafte Konklusion „George IV. wollte wissen, ob Scott Scott ist, nicht. Das vermeintliche Problem der Substitution salva veritate ist gelöst, indem gezeigt ist, dass es nichts zu substituieren gibt – die Prämissen beinhalten überhaupt keine Identitätsaussage.
Auch hier entsteht das Problem aus einer falschen Analyse. Die Kennzeichnung „der gegenwärtige König von Frankreich“ ist – wie jede Kennzeichnung – kein Eigenname. Der Satz „Der gegenwärtige König von Frankreich hat eine Glatze“ muss korrekt analysiert werden als „Es gibt genau ein Ding, das König von Frankreich ist, und dieses Ding hat eine Glatze“. Dieser Satz ist falsch.
Wenn man diesen Satz verneint, kommt man zu „Es ist nicht der Fall, dass es genau ein Ding gibt, das gegenwärtiger König von Frankreich ist, und dass dieses Ding eine Glatze hat“. Diese Verneinung ist unproblematisch.
Der Satz „Der gegenwärtige König von Frankreich hat keine Glatze“ muss analysiert werden als „Es gibt genau ein Ding, das gegenwärtiger König von Frankreich ist, und dieses Ding hat keine Glatze“. Dieser Satz ist nicht die Verneinung des ersten Satzes! Die Möglichkeit, dass beide Sätze zugleich falsch sein können, ist daher kein Problem für unsere logische Sprache.
Als Nebenprodukt von Russells Theorie der Kennzeichnungen fällt also die Beobachtung ab, dass die Verneinung von „Der gegenwärtige König von Frankreich hat eine Glatze“ keineswegs „Der gegenwärtige König von Frankreich hat keine Glatze“ lautet.3
Auf negative Existenzsätze der Form „Das runde Viereck existiert nicht“ lässt sich Russells Theorie sofort anwenden. Der gegenständliche Satz bedeutet nichts anderes als „Es ist nicht der Fall, dass es genau ein Ding gibt, das rund und das ein Viereck ist“.
Nicht unmittelbar anwendbar ist sie auf Sätze der Form „Apoll existiert nicht“, denn „Apoll“ ist nach unserem bisherigen Verständnis ein Eigenname (wenn auch nach dem Stand der Forschung bloß ein Scheinname). Russell geht so vor, dass er Scheinnamen im Sinn Freges auch als Kennzeichnungen betrachtet. Scheinnamen sind Kennzeichnungen, die nichts bezeichnen. Eine Aussage über Apoll „besagt etwas, was wir durch Einsetzung all dessen erhalten, was in einem Lexikon der Antike unter Apoll eingetragen ist“4.
Die Aussage „Pegasus existiert nicht“ besagt nach der Theorie Russells somit etwa folgendes: „Das geflügelte Pferd existiert nicht“; diese Aussage lässt sich leicht analysieren, nämlich als „Es ist nicht der Fall, dass es genau ein Ding gibt, das ein Pferd ist und Flügel hat“.
Nach unserem bisherigen Wissensstand bezeichnet jeder Name genau einen Gegenstand. Diese zweistellige Namensrelation ⟨Name, Gegenstand⟩ (vgl. Seite §) ist sehr einfach und hat uns bisher keine Probleme bereitet.
Da unsere Namensrelation nur zweistellig ist, kann eine Aussage, in der ein Name vorkommt, nur eine Aussage über den Gegenstand sein, den der Name bezeichnet. So kommt in der Aussage „Der Abendstern ist am Abendhimmel sichtbar“ der Name „der Abendstern“ vor. Die Aussage hat natürlich nicht den Namen „Abendstern“ zum Thema (der Sprachausdruck „der Abendstern“ ist auch nicht am Himmel sichtbar), sondern den Gegenstand „Abendstern“, also den Himmelskörper dieses Namens.
Die beiden Sätze
| (1) | Der Abendstern ist der Abendstern. |
| (2) | Der Abendstern ist der Morgenstern. |
sind von völlig unterschiedlicher Qualität. Satz (1) ist eine Trivialität oder zumindest ein Faktum, an dem ein Normalsterblicher nicht zweifelt. In unsere logische Sprache übersetzt, lautet Satz (1) a = a. Dieser Satz ist ein Theorem, denn er lässt sich ohne jede Prämisse beweisen.5
Satz (2) liefert die Information, dass der Himmelskörper, den man am Morgenhimmel sieht, derselbe ist wie jener, den man am Abendhimmel wahrnimmt. Dabei handelt es sich um ein empirisches Ergebnis der Astronomie, das keineswegs selbstevident ist; es zu erzielen bedurfte intensiver Forschung.
Tatsächlich muss Satz (2) auch völlig anders übersetzt werden, nämlich als a = b. Diese Aussage ist kein Theorem, denn die Tatsache, dass am Morgenhimmel und am Abendhimmel derselbe Himmelskörper (übrigens der Planet Venus) am deutlichsten sichtbar ist, ist keine logische Notwendigkeit: ⁄⊢ a = b.
Wenn wir an der eingangs formulierten Meinung festhalten, dass ein Satz ausschließlich die Gegenstände zum Thema hat, deren Namen in ihm vorkommen, dann haben wir ein Problem. Die Namen „Morgenstern“ und „Abendstern“ bezeichnen beide den Planeten „Venus“. Demnach sagen beide Sätze aus, dass der Planet Venus mit sich selbst identisch ist. Diese Feststellung ist trivial und liefert uns keine neue Erkenntnis; ihretwegen bedürfte es keiner Astronomie.
Gottlob Frege schlägt in seiner bedeutenden Arbeit Über Sinn und Bedeutung6 vor, die Namensrelation als dreistellig aufzufassen:
,  ⟩
⟩ Dabei ist der Gegenstand, den der Name bezeichnet. Neu ist die Komponente ;
sie beschreibt Frege als „Art des Gegebenseins“ – gemeint ist die Art, wie der Name
uns den Gegenstand gibt, nahebringt, vermittelt. Was mit diesem „Geben“ gemeint
ist, soll am Beispiel der beiden Namen „Abendstern“ und „Morgenstern“ deutlich
gemacht werden:
Der Name „Abendstern“ bezeichnet den Planeten Venus; dabei ist uns Venus gegeben als derjenige Himmelskörper, der am Abendhimmel am deutlichsten zu sehen ist. Die Namensrelation für „Abendstern“ wäre daher ⟨„Abendstern“, „jener Himmelskörper, der am Abendhimmel am deutlichsten zu sehen ist“, der Planet Venus⟩.
Der Name „Morgenstern“ bezeichnet ebenfalls den Planeten Venus; hierbei ist uns Venus jedoch gegeben als derjenige Himmelskörper, der am Morgenhimmel am deutlichsten zu sehen ist. Die Namensrelation für „Morgenstern“ wäre daher ⟨„Morgenstern“, „jener Himmelskörper, der am Morgenhimmel am deutlichsten zu sehen ist“, der Planet Venus⟩.
Entgegen seiner sonstigen Gewohnheit wählt Frege für die Komponenten und
seiner Namensrelation etwas unglückliche Namen: für benützt er das
Wort „Sinn“, für das Wort „Bedeutung“. Dieser Gebrauch weicht vom
umgangssprachlichen Gebrauch der beiden Wörter doch deutlich ab; man muss in
philosophischen Texten daher oft aufpassen, was mit den Wörtern „Sinn“
und „Bedeutung“ tatsächlich gemeint ist. Viele Autoren bemühen sich, die
Gefahr einer Verwechslung zu verringern, indem sie für die Komponente die
Formulierung „Sinn im Fregeschen Sinn“ oder kürzer „Fregescher Sinn“ und für die
Komponente die Formulierung „Bedeutung im Fregeschen Sinn“ oder
„Fregesche Bedeutung“ benützen. Es ist auch nicht unüblich, den Wörtern
„Sinn“ und „Bedeutung“ ein Subskript „F“ (für „Frege“) nachzustellen,
wenn sie im Sinne von Freges („SinnF “) bzw. („BedeutungF “) gemeint
sind.
Mit der dreistelligen Namensrelation Freges lässt sich das Problem der Sätze (1) und (2) sofort lösen. Satz (1) ist tatsächlich trivial; hier werden zwei Namen gleichgesetzt, die sowohl denselben SinnF als auch dieselbe BedeutungF haben. Anders Satz (2): Wohl haben die beiden gleichgesetzten Namen dieselbe BedeutungF, bezeichnen also denselben Gegenstand. Ihr SinnF ist aber ein anderer, und darin begründet sich der Erkenntnisgewinn, den uns Satz (2) verschafft.
Freges Theorie löst auch die Probleme Russells; eine negative Existenzbehauptung sagt, dass der SinnF, den ein Name ausdrückt, keine BedeutungF gibt. So wird der Name „Pegasus“ für viele von uns den Sinn „das geflügelte Pferd“ ausdrücken. Zu sagen, Pegasus existiere nicht, bedeutet dann bloß darauf hinzuweisen, dass der Name nichts bezeichnet. Sinnlos ist der Name dagegen nicht, denn einen SinnF hat er gerade.
Frege vertritt nachdrücklich die Meinung, dass in einer Wissenschaftssprache (und insbesondere in einer logischen Sprache) bedeutungF-lose Namen nicht vorkommen dürfen: Eine physikalische Diplomarbeit über die Atomstruktur des Steins der Weisen oder eine linguistische Dissertation über das Klingonische verfehlt jedes Ziel; die Namen „der Stein der Weisen“ und „die klingonische Sprache“ haben keine BedeutungF und damit in der Wissenschaft nichts verloren. Unsere logische Sprache erfüllt Freges Anforderung, weil alle Individuenkonstanten eine BedeutungF haben.
Für den Wahrheitswert eines Satzes ist ausschließlich die BedeutungF der in ihm vorkommenden Namen ausschlaggebend.7 Der wahre Satz „Der Abendstern ist ein Planet“ bleibt wahr, wenn ich den Namen „Abendstern“ durch einen Namen derselben BedeutungF ersetze: „Der Morgenstern ist ein Planet“. Das Prinzip der Substitution salva veritate (unsere Regel der = B) bleibt also unverändert gültig.
Frege argumentiert, dass auch Sätze Namen sind.8 Ein wahrer Satz ist ein Name des Wahren, ein falscher Satz ist ein Name des Falschen. Das Wahre, das Falsche und der SinnF eines Satzes sowie der SinnF eines Namens sind platonistische, nichtphysikalische Gegenstände, die außerhalb von Raum und Zeit existieren.9
Da die Theorie Freges weitaus weiter reicht, als ich hier andeuten konnte, und da die Interpretationen dieser Theorie nicht einheitlich sind, möchte ich die Leserin ersuchen, den Originalaufsatz Über Sinn und Bedeutung10 zu lesen.
Die Bedeutungstheorie Freges ist nicht ohne Vorläufer. Die ersten, die ähnliche Gedanken entwickelten, sind zweifellos die Stoiker. Ihr λϵκτóν (Lekton) ist vermutlich dasselbe wie Freges SinnF.11 Eine jüngere elegante Theorie, die auch weniger platonische Leser erfreuen dürfte, ist die Carnaps12.
Das logische Quadrat ist ein Diagramm, das die Verhältnisse zwischen bestimmten Aussagen und deren Negationen darstellt.
An den Ecken dieses Quadrats sind vier Sätze aufgeschrieben: „Alle Schweine sind rosa“, „Keine Schweine sind rosa“, „Einige Schweine sind rosa“ und „Nicht alle Schweine sind rosa.“ Je zwei Sätze, die an den Enden einer der sechs Linien (vier Seiten und zwei Diagonalen) aufgeschrieben sind, stehen zueinander in einem bestimmten Verhältnis:
Die Literaturliste ist in höchstem Maß subjektiv und vom Umfang her auf ein Minimum reduziert. Alle Werke sind Literatur für Anfänger; insbesondere die beiden Werke Lemmon und Mates sind Standardwerke in Einführungskursen.
Das Einführungsbuch ist sicherlich Lemmon; hierin wird derselbe Kalkül des natürlichen Schließens behandelt wie im vorliegenden Skriptum und häufig in der Vorlesung. Gelegentlich beklagen sich Leser über das Fehlen von Lösungen zu den Übungsbeispielen, das es bei Unklarheiten und im Fall von Zweifel erforderlich macht, einen Sachkundigen zu Rate zu ziehen.
Allen behandelt einen geringfügig modifizierten Lemmon-Kalkül und deckt exakt den Stoff der Einführungsvorlesung ab. Das Buch enthält zahlreiche Beispiele, darunter etliche mit Lösungen, ist aber nicht für das Selbststudium, sondern als Textmaterial zu einer Vorlesung gedacht. Weiterführende Themen werden nicht angeschnitten.
Ebenfalls einen Kalkül des natürlichen Schließens, wenn auch in optisch etwas abgewandelter Form, behandelt Barwise. Dieses Buch beginnt eine Spur einfacher als Lemmon und geht eine Prise langsamer vor. Die besondere Stärke von Barwise liegt im mitgelieferten Macintosh-Programm „Tarski’s World“, das dem Computerbesitzer das Erlernen der Materie erleichtert.
Wer eine besonders große Abneigung gegen formal oder mathematisch Aussehendes hat, ist wahrscheinlich mit dem Werk des Theologen Hodges – bedingt auch mit Savigny – am besten bedient. Beide bewegen sich vorwiegend im Bereich der natürlichen Sprache und von Alltagsargumentationen, vermitteln aber dennoch die Grundlagen logischen Schließens.
Hodges entwickelt einen Baumkalkül, wie er gelegentlich auch in der Vorlesung und im Tutorium zur Sprache kommt. Das Werk ist kurzweilig und angenehm zu lesen. Zum Buch gibt es das MS-DOS-Programm „Tableau II“, das eine große Hilfe beim Erlernen des Beweisens in Tableaukalkülen ist. „Tableau II“ ist am Institut für Philosophie verfügbar.
Savigny ist ein gutes Einführungsbuch mit vielen Übungsbeispielen. Es ist zwar eine Spur trockener als sein englisches Gegenstück, Hodges, dafür sehr leicht erhältlich und mit Abstand das kostengünstigste Logikbuch.
Das anspruchsvollste der genannten Werke ist Mates. Es dringt am tiefsten in die Materie ein und bietet mehrere axiomatische Kalküle sowie Kalküle des natürlichen Schließens; zudem enthält es eine gute Übersicht über die historische Entwicklung der Logik.
Preislich liegen mit Ausnahme von Barwise und Savigny alle Werke im Bereich von ca. 200-300 Schilling. Abgesehen von Mates und natürlich Savigny liegen alle Bücher nur in englischer Sprache vor. Lemmon und Hodges können erfahrungsgemäß problemlos von jeder englischen Fachbuchhandlung bestellt werden; bei Barwise ist die Wartezeit in der Regel länger, weil es sich um ein amerikanisches Buch handelt; zugleich ist dieses Werk wegen des beiliegenden Computerprogramms das mit Abstand teuerste (ca. 600-900 Schilling). Das unterste Ende der Preisskala markiert Savigny mit einem Betrag von knapp 100 Schilling.
Die Auswahl der weiterführenden Literatur ist womöglich noch willkürlicher, jedenfalls jedoch lückenhafter als die der Einführungswerke.
Wenn man den Stoff der Einführungsvorlesung beherrscht, kann man – eventuell nach der Beschäftigung mit Mates – Kalish als nahtlose Fortführung heranziehen. Dieses Buch bietet auf seinen gut fünfhundert Seiten eine Vielzahl an tiefsinnigen Anregungen, mehrere interessante und schöne Kalküle und unzählige Übungsbeispiele, zum Teil auch mit Übungen.
Church ist Das Logikbuch. Es lässt sich vielleicht als Fortsetzung zu Kalish beschreiben. Church bietet viele Übungsbeispiele (selbstverständlich ohne Lösung), darunter auch unlösbare (auch sie ohne Lösung). Im Gegensatz zum Rest des Buches ist Kapitel 0 auch ohne Vorkenntnisse verständlich und bietet soviel wesentliche Information, dass seine Lektüre jeder Philosophin ans Herz gelegt werden muss.
Berka/Kreiser ist eine gute Sammlung zum Teil gekürzter wichtiger Texte der Logik von unterschiedlichem Schwierigkeitsgrad, darunter auch Gottlob Freges bedeutender Aufsatz Über Sinn und Bedeutung und Gerhard Gentzens Untersuchungen über das logische Schließen.
Kreiser/Gottwald/Stelzner bietet eine breite Übersicht über nichtklassische Formen der Logik. Für ein vollständiges Verständnis dürfte zumindest die erfolgreiche Bewältigung von Kalish erforderlich sein.
Klug beschäftigt sich mit einer überaus konkreten Anwendung von Logik, der Rechtsprechung, und ist sehr um die Rechtfertigung von Logik bemüht. Technisch ist dieses Werk relativ leicht verständlich.
Russell enthält den wichtigen Aufsatz On denoting in deutscher Sprache.
Carnap stellt seine Bedeutungstheorie vor, die Berührungspunkte zu der Freges hat. Das Buch ist relativ leicht zu lesen.
 , 47
, 47
Abendstern, 73
Abhängigkeit
des Ergebnisses der Anwendung einer Transformationsregel, siehe die betroffene Regel
Abkürzungen, 81–82
Ableitung, 14
Ableitungsregel, siehe Transformationsregel
actual world (engl.), siehe tatsächliche Welt
Addition
unvollständige, siehe Vernam-Chiffrierschritt
Alle, siehe Quantor
Allquantor, 15, 17
beseitigen, 30
einführen, 29
Allquantor-Beseitigung, siehe Regel der Allquantor-Beseitigung
Allquantor-Einführung, siehe Regel der Allquantor-Einführung
Alternation, siehe Disjunktion
Annahme, siehe Regel der Annahme
Antecedens, 16
Argument, 9
aussagenlogisch gültiges, siehe semantischer Schlussbegriff
gültiges, siehe gültiges Argument
ohne Prämissen, 9
prädikatenlogisch gültiges, siehe semantischer Schlussbegriff
semantisch gültiges, siehe semantischer Schlussbegriff
syntaktisch gültiges, siehe syntaktischer Schlussbegriff
arity (engl.), siehe Stelligkeit
Art des Gegebenseins, 74
Ausdrücken eines Konnektivs durch ein anderes, siehe Konnektiv
Ausdrucksbaum, siehe Syntaxbaum
Aussage, 9
übersetzen, 35
mit Leerstellen, siehe Prädikat
Aussagenlogik, 10, 16
Definition, 35
Semantik, siehe Semantik der Aussagenlogik
aussagenlogisches Konnektiv, 15
Aussagesatz, siehe Aussage
ausschließendes Oder, siehe Vernam-Chiffrierschritt
Axiom, 9
axiomatischer Kalkül, 13
Baum
Syntaxbaum, siehe Syntaxbaum
Baumkalkül, 13
Baumnotation, siehe Syntaxbaum
Bausteine, 10, 14–15
Bedeutung, 10
bei Frege, siehe Fregesche Bedeutung
BedeutungF, siehe Fregesche Bedeutung
Bedeutungslehre, siehe Semantik
Bedeutungstheorie
von Frege, siehe Freges Bedeutungstheorie
Bedingung
hinreichende, siehe Konditional
hinreichende und notwendige, siehe Bikonditional
Begriff, 61–62
beliebiger Name, 15
Beschreibung
bestimmte, 50
Beseitigungsregel, 23
für ein Konnektiv, siehe Regel der Beseitigung des gewünschten Konnektivs
Besen
Verzehr, siehe Verzehr eines Besens
bestimmte Beschreibung, 50
Beweis, 14
indirekter, siehe Regel der Negationseinführung
Bikonditional, 15
Binärarithmetik
als Hilfe beim Erstellen von Wahrheitstabellen, siehe Wahrheitstabelle aufstellen
Blatt, 18
Carnap, Rudolf, 77
das Falsche, 75
das Wahre, 75
De Morgan
Satz von, 46
De Morgan, Augustus, 46
Deduktionstheorem, 27
Definition
eines Begriffs, siehe den zu definierenden Begriff
deklarativer Satz, siehe Aussage
die meisten, siehe unpräziser Quantor
Disjunkt, 16
typisches, siehe typisches Disjunkt
Disjunktion, 15, 16
beseitigen, 26
einführen, 25
Semantik der, 37
Wahrheitstabelle der, 40
Diskursuniversum, 53
leeres, 53
Domäne, siehe Diskursuniversum
domain (engl.), siehe Diskursuniversum
Doppelpfeil, siehe Bikonditional
doppelte Negation, siehe Negation
doppelte Verneinung, siehe Negation
dreistellige Namensrelation, 73
duplex negatio confirmat (lat.), siehe Regel der Nicht-Nicht-Beseitigung
Eigenname, 49–50
übersetzen, 65
Methode Quines, 66
bestimmte Beschreibung, 50
eigentlicher Eigenname, 50
Kennzeichnung, 50
kollektiver, 50
mass terms (engl.), 50
non count nouns (engl.), 50
Pronomen im Singular, 50
Scheinname, siehe Scheinname
bei Russell, 72
singularia tantum (lat.), 50
eigentlicher Eigenname, 50
Einführungsregel, 23
für ein Konnektiv, siehe Regel der Einführung des gewünschten Konnektivs
Einschränkung
bei der Allquantor-Einführung, 30
bei der Existenzquantor-Beseitigung, 32
Endknoten, 18
erfüllbarer Satz, 60
Existentialquantifikator, siehe Existenzquantor
Existenz, 51
Existenzbehauptung
negative, 66, 74
bei Frege, 74
Russells Problem, 70, 72
positive, 66
Existenzquantor, 15, 17
beseitigen, 31
einführen, 31
Existenzquantor-Beseitigung, siehe Regel der Existenzquantor-Beseitigung
Existenzquantor-Einführung, siehe Regel der Existenzquantor-Einführung
Extension
eines Prädikats, 57
Fürwort, siehe Pronomen
Fallunterscheidung, siehe Regel der Oder-Beseitigung
Falsche
das, 75
Formationsregel, 10, 16–18
Frege, Gottlob, 49, 61
Freges Bedeutungstheorie, 73–77
Fregesche Bedeutung, 74
Fregescher Sinn, 74
freie Logik, 53
funktional vollständig, 45–47
fuzzy logic (engl.), siehe Unpräzise Logik
gültiges Argument, 14, 35
Gültigkeit
eines Arguments, siehe gültiges Argument
Gegebensein
bei Frege, 74
Gegenbeispiel, 47, 48, 61
Gentzen, Gerhard, 13
Gentzen-Kalkül, siehe Kalkül des natürlichen Schließens
Gesetz von, siehe unter dem Namen des Autors
Gruppierungszeichen, siehe Klammer
Herbrand, Jaques, 27
Herleitung, siehe Ableitung
Beweis, siehe Beweis
eines Theorems, siehe Theorem
Hewlett-Packard, 23
hinreichende Bedingung, siehe Konditional
hinreichende und notwendige Bedingung, siehe Bikonditional
Identität
beseitigen, 34
einführen, 33
Identitätsaussage
empirische, 73
triviale, 73
Identitätsbeseitigung
Russells Problem, 69, 71
Implikation, siehe Konditional
materiale, siehe Konditional
indirekter Beweis, siehe Regel der Negationseinführung
Individuenkonstante, 14
Semantik, siehe Semantik
Individuenvariable, 15
Infix-Notation, siehe Peano-Russell-Notation
Interpretation, 59
Jaśkowsky, Stanisław, 13
Jaśkowsky-Kalkül, siehe Kalkül des natürlichen Schließens
Jeder, siehe Quantor
jedes mögliche Konnektiv, siehe Konnektiv
Junktor, siehe Konnektiv
Junktorenlogik, siehe Aussagenlogik
Kalkül, 11, 13
axiomatischer, siehe Axiomatischer Kalkül
Baumkalkül, siehe Baumkalkül
des natürlichen Schließens, 13
Regelkalkül, siehe Regelkalkül
Tableaukalkül, siehe Tableaukalkül
Kausalität, 37
Kennzeichnung, 50
Kennzeichnungstheorie Russells, 71
Klammer, 15
Klammereinsparungsregel, 18
Knoten, 18
Endknoten, 18
Kollektiver Eigenname, 50
komplexer Satz
Wahrheitstabelle eines, 41
Konditional, 15, 16
beseitigen, 28
einführen, 27
Semantik des, 37
Wahrheitstabelle des, 41
Konjunkt, 16
Konjunktion, 15, 16
beseitigen, 24
einführen, 24
Semantik der, 36
Wahrheitstabelle, 40
Konklusion, 9
Konnektiv
aussagenlogisches, 15
Beseitigen eines Konnektivs, siehe Beseitigungsregel
das in unserer logischen Sprache nicht vertreten ist, siehe jedes mögliche Konnektiv
durch ein anderes Konnektiv ausdrücken, 45
Einführen eines Konnektivs, siehe Einführungsregel
jedes mögliche, 43–46
Konnektivmenge
funktional vollständige, siehe funktional vollständig
Konsequens, 16
konstant wahrer Satz, siehe Tautologie
konträr, 79
Kontradiktion, siehe Widerspruch
kontradiktorisch, 79
leeres Diskursuniversum, siehe Diskursuniversum
Leerstelle, 51
Leibnitz, siehe Leibniz
Leibniz, 47
Lekton, 77
Linguistik, 10
Liste
Prämissenliste, siehe Prämissenliste
Logik
Aussagenlogik, siehe Aussagenlogik
freie, 53
Junktorenlogik, siehe Aussagenlogik
unpräzise, siehe Unpräzise Logik
logische Sprache, siehe Sprache
logisches Quadrat, 79
mögliche Welt, 36
Marquand, Allan, 38
mass term (engl.), siehe Eigenname
materiale Implikation, siehe Konditional
Metasprache, 10, 16
Modell, 60
modus ponendo ponens (lat.), siehe Regel der Pfeil-Beseitigung
modus ponens (lat.), siehe Regel der Pfeil-Beseitigung
Morgenstern, 73
Morphologie, siehe Syntax
Name, siehe Eigenname
beliebiger, siehe beliebiger Name
Namensbeziehung, siehe Namensrelation
Namensrelation, 50, 73
dreistellige, 73
zweistellig, 53
zweistellige, 50, 73
NAND, 46
Natürliches Schließen, siehe Kalkül des natürlichen Schließens
Negation, 15, 17
beseitigen, 29
einführen, 28
Semantik der, 36
Wahrheitstabelle der, 41
Negation, im logischen Quadrat, 79
Negationseinführung, siehe Regel der Negationseinführung
Nicht-Nicht-Beseitigung, siehe Regel der Nicht-Nicht-Beseitigung
nichtausschließendes Oder, siehe Disjunktion
Nichtoder, siehe NOR
Nichts, siehe Quantor
Nichtund, siehe NAND
Niemand, siehe Quantor
non count noun (engl.), siehe Eigenname
NOR, 46
Notation
Baumschreibweise, siehe Syntaxbaum
Infix, siehe Peano-Russell-Notation
Peano-Russell-Notation, siehe Peano-Russell-Notation
polnische, siehe polnische Notation
Postfix, siehe UPN
umgekehrte polnische Notation, siehe UPN
UPN, siehe UPN
nullstelliger Prädikatbuchstabe, siehe Satzbuchstabe
Objektsprache, 10
Oder
ausschließendes, siehe Vernam-Chiffrierschritt
nichtausschließendes, siehe Disjunktion
Oder-Beseitigung, siehe Regel der Oder-Beseitigung
Oder-Einführung, siehe Regel der Oder-Einführung
parse tree (engl.), siehe Syntaxbaum
Peano-Russell-Notation, 18
Peirce, Charles Sanders, 38
Pfeil, siehe Konditional
Pfeil-Beseitigung, siehe Regel der Pfeil-Beseitigung
Pfeil-Einführung, siehe Regel der Pfeil-Einführung
Polnische Notation, 21–23
Postfix-Notation, siehe UPN
Prädikat, 51
übersetzen, 62
arity (engl.), siehe Stelligkeit
Begriff, siehe Begriff
Extension, 57
Stelligkeit, siehe Stelligkeit
Prädikatbuchstabe, 14
arity (engl.), siehe Stelligkeit
nullstelliger, siehe Satzbuchstabe
Semantik, siehe Semantik
Stelligkeit, siehe Stelligkeit
Prädikatenlogik
Semantik, siehe Semantik
Prämisse, 9
Prämissenliste, siehe Prämissenliste
Prämissenliste, 14
Pragmatik, 10
Problem
der negativen Existenzsätze, 70, 72
der Substitution salva veritate, 69, 71
des Tertium non datur, 70, 72
Russels
gelöst von Frege, 74
Produktionsregel, 16
Pronomen im Singular, 50
proposition (engl.), siehe Aussage
Quadrat, logisches, 79
Quantifikator, siehe Quantor
Quantor, 15, 51–52
übersetzen, 65
Allquantor, siehe Allquantor
Existentialquantifikator, siehe Existenzquantor
Existenzquantor, siehe Existenzquantor
Semantik, siehe Semantik
Universalquantifikator, siehe Allquantor
unpräziser, 65
Quine, Willard Van Ornam, 66
reductio ad absurdum (lat.), siehe Regel der Negationseinführung
schwache, siehe Regel der Negationseinführung
Regel
Ableitungsregel, siehe Transformationsregel
Beseitigungsregel, siehe Beseitigungsregel
der Allquantor-Beseitigung, 30–31
der Allquantor-Einführung, 29–30
der Annahme, 23–24
der Existenzquantor-Beseitigung, 31–33
der Existenzquantor-Einführung, 31
der Identitätsbeseitigung, 34
der Identitätseinführung, 33
der Negationseinführung, 28–29
der Nicht-Nicht-Beseitigung, 29
der Oder-Beseitigung, 26–27
der Oder-Einführung, 25
der Pfeil-Beseitigung, 28
der Pfeil-Einführung, 27–28
der Und-Beseitigung, 24–25
der Und-Einführung, 24
Einführungsregel, siehe Einführungsregel
Formationsregel, siehe Formationsregel
Produktionsregel, siehe Produktionsregel
Schlussregel, siehe Transformationsregel
Transformationsregel, siehe Transformationsregel
zur Klammereinsparung, siehe Klammereinsparungsregel
zur Vereinfachung, siehe Klammereinsparungsregel
Regel der Allquantor-Einführung
Einschränkung, 30
Regel der Existenzquantor-Beseitigung
Einschränkung, 32
Regelkalkül, 13
Relation
Namensrelation, siehe Namensrelation
Russell, Bertrand, 69
Russells Kennzeichnungstheorie, 71
Russells Probleme, 69–72
Sachverhalt, 36
Satz
Aussagesatz, siehe Aussage
deklarativer, siehe Aussage
erfüllbarer, siehe erfüllbarer Satz
komplexer, siehe komplexer Satz
konstant wahrer, siehe Tautologie
unerfüllbarer, siehe unerfüllbarer Satz
vom ausgeschlossenen Dritten, siehe Tertium non datur
Satz von, siehe unter dem Namen des Autors
Satzbuchstabe, 16, 35
Satzbuchstaben
Semantik, siehe Semantik der Satzbuchstaben
Scheinname, 49
bei Russell, 72
Schließen
natürliches, siehe Kalkül des natürlichen Schließens
Schlussbegriff
semantischer, siehe semantischer Schlussbegriff, siehe semantischer Schlussbegriff
syntaktischer, siehe syntaktischer Schlussbegriff
Schlussregel, siehe Transformationsregel
Schreibweise, siehe Notation
schwache reductio ad absurdum, siehe Regel der Negationseinführung
Selbstidentität, 73
Semantik, 10, 35–77
der Aussagenlogik, 35–47
der aussagenlogischen Konnektive, 36–43
der Disjunktion, 37
der Individuenkonstanten, 53
der Konjunktion, 36
der Negation, 36
der Prädikatbuchstaben, 57
der Prädikatenlogik, 52–58
der Quantoren, 58
der Satzbuchstaben, 35–36
des Konditionals, 37
Semantischer Schlussbegriff
Aussagenlogik, 47–49
Prädikatenlogik, 58–61
Sheffer-Funktion, 47
singularia tantum (lat.), siehe Eigenname
Sinn
bei Frege, siehe Fregescher Sinn
SinnF, siehe Fregescher Sinn
Sonderzeichen, 81–82
Sprache
Bausteine, siehe Bausteine
logische, siehe Sprache
Metasprache, siehe Metasprache
Objektsprache, siehe Objektsprache
Sprachwissenschaft, siehe Linguistik
state of affairs, siehe mögliche Welt
Stelligkeit, 16, 51
Stoa, siehe Stoiker
Stoiker, 38, 77
subkonträr, 79
Substitution salva veritate, siehe Regel der Identitätsbeseitigung
Syntaktischer Schlussbegriff, 14
Syntax, 10, 13–34
Syntaxbaum, 18–21
Blatt, 18
Endknoten, 18
Knoten, 18
Endknoten, 18
Wurzel, 18
Tabelle
Wahrheitstabelle, siehe Wahrheitstabelle
Tafel
Wahrheitstafel, siehe Wahrheitstafel
tatsächliche Welt, 36
Tautologie, 9, 43
Tertium non datur
Russells Problem, 70, 72
Theorem, 14
Deduktionstheorem, siehe Deduktionstheorem
Tilde, siehe Negation
Transformationsregel, 11, 23–34
typisches Disjunkt, 32
umgekehrte polnische Notation, siehe UPN
Und, siehe Konjunktion
Und-Beseitigung, siehe Regel der Und-Beseitigung
Und-Einführung, siehe Regel der Und-Einführung
unerfüllbarer Satz, 60
Universalquantifikator, siehe Allquantor
universe of discourse (engl.), siehe Diskursuniversum
Unpräzise Logik, 65
unpräziser Quantor, siehe Quantor
unvollständige Addition, siehe Vernam-Chiffrierschritt
UPN, 23
Vereinfachungsregel, siehe Klammereinsparungsregel
Verfahren
zum Ausdrücken eines Konnektivs durch andere, siehe Konnektiv
Verlauf
der Wahrheitswerte, siehe Wahrheitswertverlauf
Vernam, Gilbert S., 45
Vernam-Chiffrierschritt, 45
Verneinung, siehe Negation
doppelte, siehe Negation
Verzehr eines Besens, 37
viele, siehe unpräziser Quantor
vollständig
funktional, siehe funktional vollständig
Wahre
das, 75
Wahrheit, siehe Wahrheitswert
Wahrheitstabelle, 38–43
aufstellen, 39
der Disjunktion, 40
der Konjunktion, 40
der Negation, 41
des Konditionals, 41
eines komplexen Satzes, 41
Wahrheitstafel, siehe Wahrheitstabelle
Wahrheitswert, 35
Wahrheitswertverlauf, 37
Wahrheitswertzuordnung, 36
Welt
mögliche, siehe mögliche Welt
tatsächliche, siehe tatsächliche Welt
wenige, siehe unpräziser Quantor
Widerspruch, 29
Wirkung
von Zeichen auf den Hörer, siehe Pragmatik
Wurzel, 18
Zeichen, 81–82
Zuordnung
von Wahrheitswerten, siehe Wahrheitswertzuordnung
zweistellige Namensrelation, siehe Namensrelation, 73